Start with the workload
Batch inference is the unglamorous half of serving LLMs — no user waiting on a token, just a queue of work to grind through offline: classify a few hundred million records, pull fields from a document archive, score a dataset, summarize a support-ticket backlog. The jobs are huge, latency-tolerant, and the bill is almost all raw token volume. Which is why someone always asks: can we just self-host this instead of paying an API?
It’s tempting to assume the answer is yes — self-hosting must be cheaper. It often isn’t. Run an open model at low utilization, with GPUs sitting idle and an engineer babysitting the deployment, and the same model on your own hardware can cost more than the API you were trying to escape. And when self-hosting does win, what it usually beats is the expensive frontier labs — the cheap open-model APIs already undercut those by 5–57× for free: DeepSeek V4-Pro serves strong workhorse-tier quality at $0.435 in / $0.87 out per 1M tokens, about 35× cheaper on output than GPT-5.5 ($5 / $30) — and 57× cheaper than the priciest frontier model, Claude Fable 5 ($10 / $50). You don’t need AIBrix, a GPU, or this blog post to beat OpenAI on price.
So the question worth answering is harder:
Given how cheap the open-model APIs already are, when does self-hosting actually pay off — and what does AIBrix add?
It comes down to three things — matching capability, pricing the managed options honestly, and working out what self-hosting really costs — then a decision tree for when self-hosting wins. (Cold start gets one paragraph; for hour-long batch jobs it barely matters.)
Match capability, not model names
You can’t compare prices across models of different quality. So we tier models by a benchmark basket — the Artificial Analysis Intelligence Index (AA-II) as the spine, cross-checked against GPQA, SWE-bench Verified, LiveCodeBench, and LMArena — and compare price within a tier. AA-II is a single ~0–100 score that rolls reasoning, math, coding, and knowledge benchmarks into one “how capable” number (higher = smarter); the tier bands below are AA-II v4.1 ranges (as of mid-June 2026):
| Tier | Closed (API-only) | Best self-hostable open peer | Verdict |
|---|---|---|---|
| Frontier (AA-II ~55–60) | Claude Fable 5, Opus 4.8, GPT-5.5 | None reaches it | Concede — pay the API |
| Workhorse (AA-II ~43–51) | Gemini 3.5 Flash, Claude Sonnet 4.6, Gemini 3.1 Pro | GLM-5.2, DeepSeek V4-Pro, MiniMax-M3 | Open leads |
| Efficient (AA-II ~24–42) | Claude Haiku 4.5, Gemini 3.1 Flash-Lite | Qwen3.6-27B | Open wins |
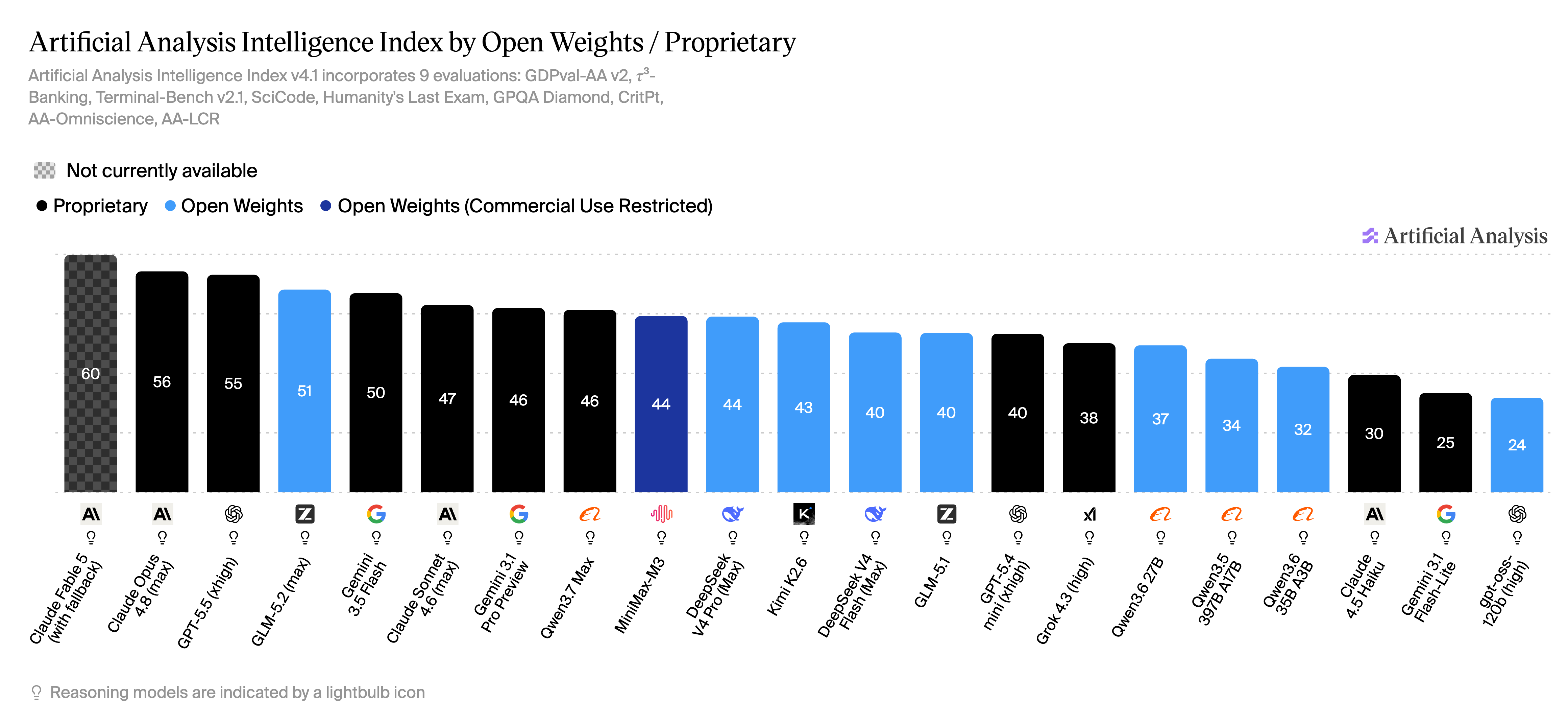 Artificial Analysis Intelligence Index (v4.1), colored by license — black = proprietary, blue = open-weight (dark blue = open but commercial-use-restricted). The coloring is the thesis. The frontier is all black: Claude Fable 5 (60), Opus 4.8 (56), GPT-5.5 (55) — no open model reaches it. But right below it, the top open model — GLM-5.2 (51, MIT) — edges Gemini 3.5 Flash (50) to lead the workhorse tier, only ~4 points off the frontier floor. And at the efficient end the colors flip again: Qwen3.6-27B (37) sits above Claude Haiku 4.5 (30) — open wins the tier most batch jobs live in. Source: Artificial Analysis.
Artificial Analysis Intelligence Index (v4.1), colored by license — black = proprietary, blue = open-weight (dark blue = open but commercial-use-restricted). The coloring is the thesis. The frontier is all black: Claude Fable 5 (60), Opus 4.8 (56), GPT-5.5 (55) — no open model reaches it. But right below it, the top open model — GLM-5.2 (51, MIT) — edges Gemini 3.5 Flash (50) to lead the workhorse tier, only ~4 points off the frontier floor. And at the efficient end the colors flip again: Qwen3.6-27B (37) sits above Claude Haiku 4.5 (30) — open wins the tier most batch jobs live in. Source: Artificial Analysis.
Three honest caveats, because the landscape moved and the details matter:
- The frontier is closed-only. No self-hostable open model matches the closed frontier — Claude Fable 5, Opus 4.8, GPT-5.5 — today. The best deployable open model, GLM-5.2, now lands just ~4 AA-II points below the frontier floor (51 vs GPT-5.5’s 55) — close, but not there — and the gap is larger on independently-verified agentic coding (Opus 4.8 posts a third-party-verified 88.6% on SWE-bench Verified; the open models’ competing 80%+ figures are vendor self-reported). If your batch job needs frontier quality, pay for the frontier — there’s no open or budget substitute.
- Workhorse is parity — if not an open win. The top open model, GLM-5.2 (51), actually edges the best closed workhorse model, Gemini 3.5 Flash (50), and clears Claude Sonnet 4.6 (47) and Gemini 3.1 Pro (46); DeepSeek V4-Pro and MiniMax-M3 (both 44) sit a notch behind. These are real, aggregate-verified results — this is where self-hosting credibly replaces, and can even beat, a mid-tier API.
- Efficient is where open pulls ahead. Qwen3.6-27B (a 27B dense model, trivial to self-host) beats Claude Haiku 4.5 on the aggregate index — 37 vs 30 AA-II, both in reasoning mode for an apples-to-apples read — in a package small enough to run one-per-GPU. Most batch workloads — classification, extraction, summarization, tagging — live in this tier. This is the strongest self-hosting pitch: better quality than the closed efficient tier, at a fraction of the cost.
Licensing: the open models we’d actually self-host are permissively licensed for commercial use — DeepSeek V4 and GLM-5.2 are MIT, Qwen3.6 is Apache-2.0. (MiniMax-M3 is the exception — open-weight but commercial-use-restricted, the dark-blue bar above.)
Takeaway: the cost story is honest and strong in Workhorse and Efficient, and we concede Frontier. The rest of this post is about those two tiers.
Note — multimodal is a separate study. This post sticks to text LLM batch inference. Multimodal batch workloads — bulk image/document understanding, image generation, and video indexing — have a different capability and cost profile (and, for self-hosting, an even more favorable one), so they get a dedicated follow-up post rather than being compressed in here.
What the managed APIs cost (USD per 1M tokens)
Within a tier, managed options span two orders of magnitude:
| Tier | Model | In | Out | Note |
|---|---|---|---|---|
| Frontier | Claude Fable 5 | 10.00 | 50.00 | closed frontier — newest and priciest |
| Frontier | Claude Opus 4.8 | 5.00 | 25.00 | closed frontier |
| Frontier | OpenAI GPT-5.5 | 5.00 | 30.00 | closed frontier |
| Workhorse | Gemini 3.1 Pro | 2.00 | 12.00 | frontier priced, workhorse-tier on v4.1 |
| Workhorse | Claude Sonnet 4.6 | 3.00 | 15.00 | closed workhorse |
| Workhorse | GLM-5.2 (first-party) | 1.40 | 4.40 | open weights (MIT) — the workhorse leader |
| Workhorse | DeepSeek V4-Pro (first-party) | 0.435 | 0.87 | open weights, first-party API |
| Workhorse | DeepSeek V4-Pro on Fireworks/DeepInfra | 1.74 | 3.48 | same weights, ~4× DeepSeek’s own price |
| Efficient | Claude Haiku 4.5 | 1.00 | 5.00 | closed efficient |
| Efficient | Gemini 3.1 Flash-Lite | 0.25 | 1.50 | cheapest closed efficient |
| Efficient | DeepSeek V4-Flash | 0.14 | 0.28 | open weights — ~18× cheaper output than Haiku, cheapest credible row |
Batch endpoints (OpenAI, Anthropic, Google) take another −50% on both input and output, and most other providers offer comparable batch or off-peak discounts; prompt caching takes up to −90% on cached input.
Two findings reshape the whole comparison:
- The model makers’ own first-party APIs are the real price floor, not the premium closed labs — 5–35× cheaper, biggest gap on output tokens (which dominate real bills).
- Third-party model hosts charge ~3–4× the first-party price for identical weights (DeepSeek V4-Pro is $1.74/$3.48 on Fireworks vs $0.435/$0.87 from DeepSeek itself). You’re paying for managed infrastructure, SLAs, and support.
This is the crux for self-hosting: you’re not really competing with DeepSeek’s $0.43 floor — you’re competing with the $1.74 third-party-host markup, and with the constraint that some workloads simply cannot send data to an external API at all. That’s the gap AIBrix self-hosting fills.
What it costs to run it yourself
Self-hosting cost is first-principles:
$/1M tokens = GPU_$/hr × GPU_count × 1e6 / (throughput_tok_s × utilization × 3600)
GPU prices we’ll use (on-demand, mid-June 2026; RunPod bills per-second, Lambda per-minute, neither offers true spot):
| GPU | RunPod (secure, on-demand) | Lambda (on-demand) |
|---|---|---|
| H100 SXM 80GB | $3.29 | $4.29 (single) |
| A100 80GB PCIe | $1.39 | $1.99 (40GB) |
Throughput swings ±30% with engine version, quant, and sequence mix — so every figure below is measured (vLLM, offline throughput driven to saturation), not estimated. Measured mid-June 2026 on the 800-in / 150-out extraction profile:
| Model | Config | Throughput (tok/s) | Self-host $/1M (≈U90) |
|---|---|---|---|
| Qwen3.6-27B | 1× H100, FP8 (native) | ~10,300 | ~$0.10 ← cheapest |
| Qwen3.6-27B | 1× A100, FP8 (dequantized — no Ampere FP8) | ~2,400 | ~$0.18 |
At high utilization the measured floor is ~$0.10/1M on the H100 — low cents, well under the third-party hosts and even within range of the cheap first-party APIs. The GPU you pick is itself a big cost lever — and not in the obvious direction: the H100 costs 2.4× the A100 per hour, yet comes out cheaper per token ($0.10 vs ~$0.18), because it’s ~4× faster and has native FP8 — the A100 (Ampere) has no FP8 tensor cores, so the same checkpoint dequantizes and runs ~4× slower. Match the card to the model and quant, and the “expensive” GPU is often the cheap one. The real catch is the “at high utilization” qualifier — that, not cold start, decides self-host vs. managed, so we lay it out as a decision tree below.
A quick note on cold start
When you self-host, the GPU meter runs during model load + engine init before the first token — about a minute for a 27B, a few minutes for a 70B-class model on several GPUs. A managed API hides this cost; you pay it explicitly.
For realistic batch — jobs that run an hour or more — it’s a rounding error: a 3-minute warm-up on a 60-minute job is ~5%, and on a fleet that keeps engines warm it amortizes away entirely. Cold start only dominates if you boot a fresh cluster for one tiny job, which isn’t how batch runs — so we assume long-running, high-utilization execution and don’t dwell on it. (A genuinely tiny, sporadic workload is itself a signal to use a managed API — see the decision tree.)
Putting it together — the decision tree

The crossover point — the single number that answers “should I self-host?” — is a utilization, and our runs pin it: the self-hosted H100 beats the closed efficient API (Haiku 4.5) above only ~10% GPU utilization (a trivially low bar), but merely ties the cheapest first-party open API (DeepSeek V4-Flash) even at full saturation. Translation: against a closed API, self-hosting wins almost immediately; against the dirt-cheap first-party APIs it’s a price tie, so you self-host for data control, private models, or scale — not to shave the last cent.
What AIBrix Batch actually is

The cost economics above aren’t unique to AIBrix — they’re the economics of self-hosting in general. What AIBrix provides is the system that makes capturing them practical and safe at scale. Concretely, it’s more than a loop that reads a JSONL and calls vLLM:
- A persisted, event-sourced job state machine — the datastore is the source of truth, not Kubernetes annotations. Each batch is a JSON document in a pluggable metastore (Redis / S3 / GCS / TOS) with a whitelisted transition table (
created → scheduling → validating → in_progress → finalizing → finalized, pluscompleted / failed / cancelled / expiredconditions). On restart the manager rehydrates every job from the store — a crash doesn’t lose your batch. - Per-request, resumable execution. A batch can carry up to 50,000 requests; each is independently locked (Redis
NX), checkpointed, and streamed to object storage as a multipart upload keyed by line index. A worker that dies mid-batch resumes from the next un-done request instead of re-running the job — at-least-once with dedup, memory-bounded, not buffered in RAM. - Storage is pluggable, and the same backends serve two roles. The input JSONL plus the output / error files live in object storage — S3, GCS, or TOS; the job state machine and per-request progress live in the metastore — Redis, S3, GCS, or TOS (Redis when low-latency state matters; object storage for durability without standing up a database). Results are written incrementally as a multipart upload and served back through
GET /v1/files/{output_file_id}/content— no external database required. - One driver, a registry of pluggable runtimes. Every backend runs the same lifecycle (
validate → provision → wait_ready → connect → prepare → run → finalize → teardown); a new backend is a new registered Runtime, not a fork of the driver. Two are GA, both on Kubernetes: self-hosting (a K8s Job with the vLLM engine and the batch worker in one pod — the worker waits for/health, then dispatches and aggregates) and control-plane dispatch (a per-job Deployment the control plane drives over HTTP). Two more are preview — RunPod and Lambda Cloud: the Resource Manager leases a GPU box and the runtime brings up vLLM on it over SSH (on Lambda behind an SSH tunnel, so the engine is never publicly exposed). The production-honored path today is in-cluster Kubernetes. - OpenAI-faithful surface, including the accounting.
/v1/files+/v1/batches, thevalidating → in_progress → finalizing → completedlifecycle, the 24-hour window,custom_idecho, and a realusageobject —input/output/total_tokenspluscached_tokens(prefix-cache hits) andreasoning_tokens— accumulated per request and deduped on retry. Job endpoints:/v1/chat/completions,/v1/completions,/v1/embeddings. - An admin/user split that is the security and cost boundary. Users stay on the stock OpenAI SDK and name a template via
extra_body.aibrix; the only overridable field is the allowlistedengine_args— image, GPU SKU, and model source are admin-only, and any other override key is rejected with a400, never silently dropped. Templates are versioned and hot-reload from a ConfigMap with per-item error isolation. - Trough-filling raises utilization — the lever that moves $/token. Batch is latency-tolerant, so AIBrix packs it into the idle capacity your online serving leaves behind; higher effective utilization is what turns that self-hosting floor from theoretical into real, with no extra hardware.
Honest boundaries (a cost article shouldn’t oversell the system either): the self-host throughput numbers above are a single-machine, vanilla vLLM baseline — we deliberately didn’t chase peak performance. AIBrix stacks three more cost levers on top, all excluded here pending their own benchmark: gateway prefix-cache-aware routing, StormService disaggregated (prefill/decode-split) serving, and L2 KV offloading / reuse. Those are a follow-up post — so treat every number here as a floor real deployments beat, not a ceiling.
A worked example — 20K requests, end to end
Make it concrete. You have 20,000 chat-completion requests to run offline — pull structured JSON from a document archive, ~800 in / 150 out tokens each (≈ 19M tokens) — which fits comfortably in a single AIBrix batch (the per-batch ceiling is 50,000 requests). It’s a workhorse/efficient job, so run Qwen3.6-27B on a single H100. Submission is the stock OpenAI Batch flow — only the base_url changes:
from openai import OpenAI
client = OpenAI(base_url="http://<aibrix>/v1", api_key="...")
f = client.files.create(file=open("requests.jsonl", "rb"), purpose="batch")
batch = client.batches.create(
input_file_id=f.id, endpoint="/v1/chat/completions", completion_window="24h",
extra_body={"aibrix": {"model_template": {"name": "qwen3.6-27b"}}}, # admin-registered template
)
# poll batch.status → "completed"; then download client.files.content(batch.output_file_id)
One H100 stays busy for the whole job — high utilization, the regime where the self-host floor is real — and it’s a single K8s Job, not a cluster. The cost, against the alternatives you’d realistically reach for (self-host figure computed from the measured throughput above):
| This job (~19M tokens) | Cost |
|---|---|
| Self-host Qwen3.6-27B · 1× H100 (AIBrix) — AA-II 37 | ~$1.7 (from measured throughput) |
| Claude Haiku 4.5 — closed efficient API, lower quality (AA-II 30) | ~$16 |
| DeepSeek V4-Flash — cheapest managed (open), off-peak | ~$1.5 |
Self-hosting Qwen3.6-27B runs a better model than the closed efficient API — AA-II 37 vs Claude Haiku 4.5’s 30 — at ~9× less (~$1.7 vs ~$16), and your data never leaves. At the measured throughput above, this job is ~31 minutes on one H100, so its cost is essentially 0.5 hr × $3.29 (we measured the tokens/sec at saturation; the job total is that rate × volume, not a separately timed 20K run). Honest counterpoint: the cheapest managed open API (DeepSeek V4-Flash ≈ $1.5) is now a near-tie — so the case for self-hosting here is data control, a private / fine-tuned model, or sustained scale, exactly as the decision tree says.
And the self-host floor keeps dropping. The $/token isn’t static — vLLM gets faster at batch every release. On top of that, AIBrix’s gateway routing + StormService disaggregation + KV offloading stack further still (all excluded from the conservative single-machine numbers here — a follow-up post measures them). So the gap versus a managed API widens over time, not narrows.
Caveats & sources
GPU and API prices are real quotes as of mid-June 2026 but drift weekly and disagree across aggregators by 5–20% — re-verify in-console. Every self-host throughput number is measured via the benchmark (not estimated), with the model, GPU, and config logged alongside. Capability tiers use Artificial Analysis as the spine; several open “frontier-adjacent” coding scores are vendor self-reported and not independently reproduced — we do not let them close the frontier gap. (Full source list: OpenAI / Anthropic / Google / DeepSeek / z.ai / Fireworks pricing pages; Lambda & RunPod pricing; Artificial Analysis for capability; gpustack, Baseten, Spheron, databasemart throughput labs.)