🚀 AIBrix v0.7.0 Release
The pieces that make large-scale LLM inference fast — multi-engine serving, prefill/decode disaggregation, KV-cache reuse, high-throughput batch, multi-cloud GPU capacity — mostly exist already as discrete parts. The harder problem is making them compose into one platform: a KV path that serves both offload and disaggregation instead of two, a gateway that stays correct when it’s replicated, an engine choice that isn’t hard-wired, and an operational surface that doesn’t require a standing Kubernetes-and-Envoy team to drive.
AIBrix v0.7.0 is our broadest release yet — it advances the platform on every layer of the stack at once: how you operate it (a new Console), the workloads it runs (a rebuilt Batch plane), the engines and data plane underneath (first-class TensorRT-LLM, plus a KV-cache-centric disaggregated serving path that does transfer and reuse in one store), and the gateway in front (composable routing, a P/D-disaggregation router refactored across engine / KV-transfer / worker-selection axes, now highly available). Adopt the layers you need.
This release lands 242 merged PRs over three months. For the complete list of changes, commit history, and contributor details, see the AIBrix v0.7.0 Release Notes.
v0.7.0 Highlight Features
- AIBrix Management Console — A new web control plane to deploy models and run batch jobs — with OIDC login, no kubectl required.
- OpenAI-compatible Batch API — A self-hosted Batch API, OpenAI-compatible on the common endpoints: point your SDK at AIBrix, upload JSONL, and run large asynchronous jobs on your own GPUs — or, in preview, on rented cloud GPUs (Lambda Cloud, RunPod). No per-request API fee (you pay for the GPUs you run on), and full data control when you run it in-cluster.
- TensorRT-LLM as a first-class engine — Serve vLLM, SGLang, and now TensorRT-LLM behind one gateway, with engine-aware metrics and P/D routing.
- KV-centric P/D disaggregation — A KV-cache-centric serving path (the store sits in the middle, backed by PrisKV) that does P/D transfer and KV reuse in one layer — enabling single-node P/D without RDMA on L20-class GPUs (validated in internal testing).
- Highly-available gateway with composable routing — Blend routing algorithms with weighted soft-scoring; route P/D-disaggregated traffic through a refactored router with pluggable engine orchestration (vLLM/SGLang/TRT-LLM), KV-transfer connector (SHFS/NIXL/Mooncake), and worker-selection policy (AIBrix scores today, Mooncake Conductor next); and keep prefix-cache and load-based routing correct across a replicated, zero-downtime-upgradeable gateway via Redis state-sync.
AIBrix Management Console
Until now, most AIBrix platform operations went through kubectl and YAML. That’s the right interface for a platform team, but it’s a wall for the data scientists and application engineers who just want to deploy a model or submit a batch job. The community asked for a self-service web portal for end users (issue #1897), and v0.7.0 delivers it.
The AIBrix Management Console is a full web control plane — a React frontend backed by a Go BFF — that exposes AIBrix’s core operations through a UI:
- Model-centric deployment — Register models and manage their
ModelDeploymentTemplates (engine, accelerator type and count, quantization, parallelism, min/max replicas, autoscaling, multi-LoRA; sources include S3 and custom paths) from the browser. Templates are reusable and versioned, so the workflow is: pick your favorite model, choose the model template, deploy. - Batch jobs — Submit, list (with pagination and owner filtering), monitor, and download results for OpenAI-compatible batch jobs, including a per-job execution-detail view.
- Sign-in — OIDC login, with dev/basic auth modes for local setups.
- Console storage — the Console itself runs on a pure-Go SQLite store out of the box, or MySQL for larger deployments.
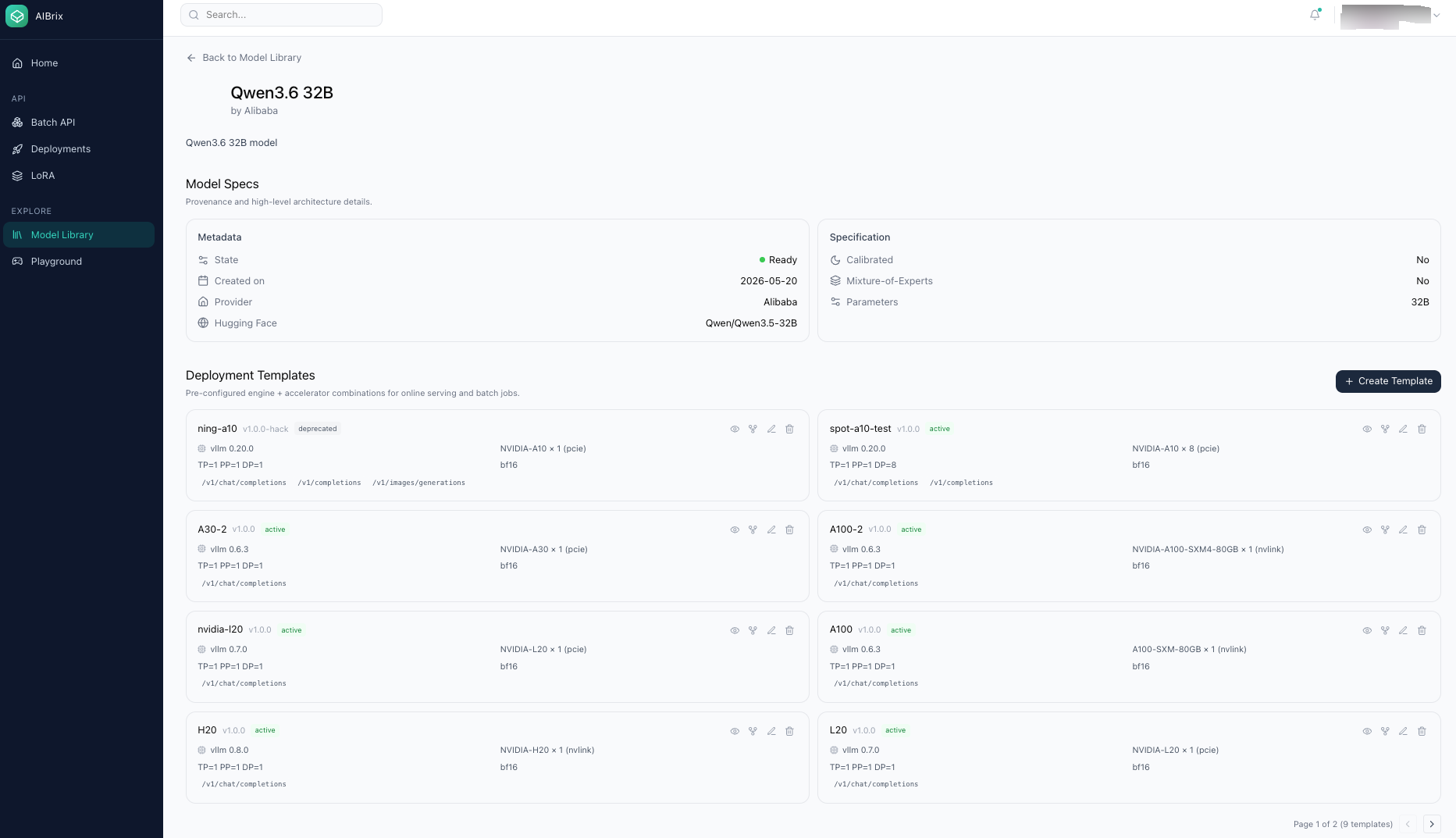 The model library and deploy form — engine, accelerator type and count, quantization, parallelism, replicas, multi-LoRA — no YAML required.
The model library and deploy form — engine, accelerator type and count, quantization, parallelism, replicas, multi-LoRA — no YAML required.
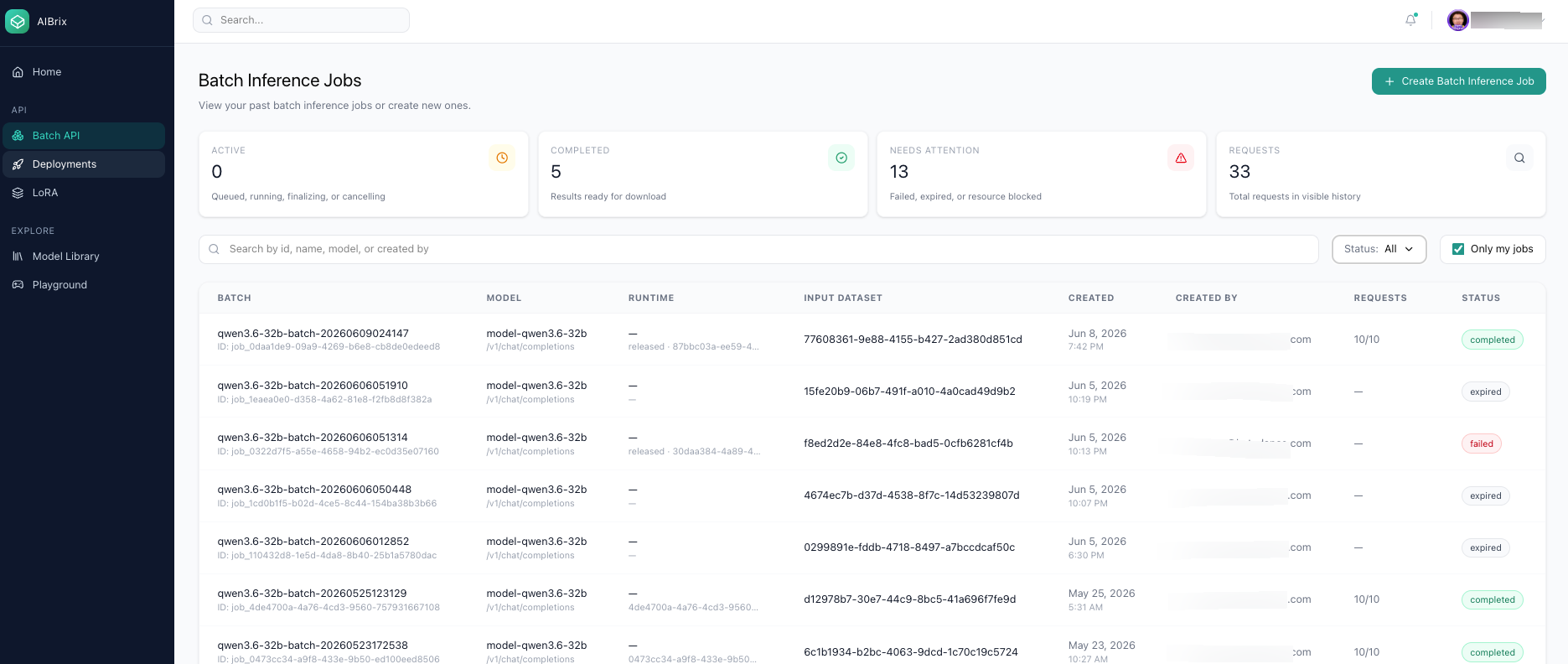 The batch jobs view: submit a job, track status with an owner filter, and drill into per-job execution details.
The batch jobs view: submit a job, track status with an owner filter, and drill into per-job execution details.
The Console is new in v0.7.0 and evolving quickly — we’re shipping it early because the self-service workflow is too valuable to hold back, and because the best way to harden it is real usage. Everything it does remains fully scriptable through the existing CRDs and APIs; the Console is an addition, never a requirement.
OpenAI-compatible Batch API
Online serving isn’t the whole story. Evaluations, dataset labeling, synthetic-data generation, and offline scoring are all batch problems — high-volume, latency-tolerant, cost-sensitive. OpenAI’s Batch API made these ergonomic, but it runs on someone else’s GPUs at per-request prices, and your data leaves your environment.
We introduced a self-hosted, OpenAI-compatible Batch API back in v0.5.0; v0.7.0 rebuilds it for production. The execution engine is new — a provider-agnostic orchestration core with an async planner and a persisted, metadata-store-backed job state machine, replacing the old controller/annotation path — and on top of it v0.7.0 adds model deployment templates, a Console UI, and the plumbing to run jobs on cloud GPU providers. The wire contract stays OpenAI-compatible: the only required change is base_url, everything else is the standard OpenAI Batch API, and an optional aibrix.model_template block — the single AIBrix extension — pins exactly how the model runs for this job. The payload below is the superset; every later section just varies one field of it (or omits the block entirely):
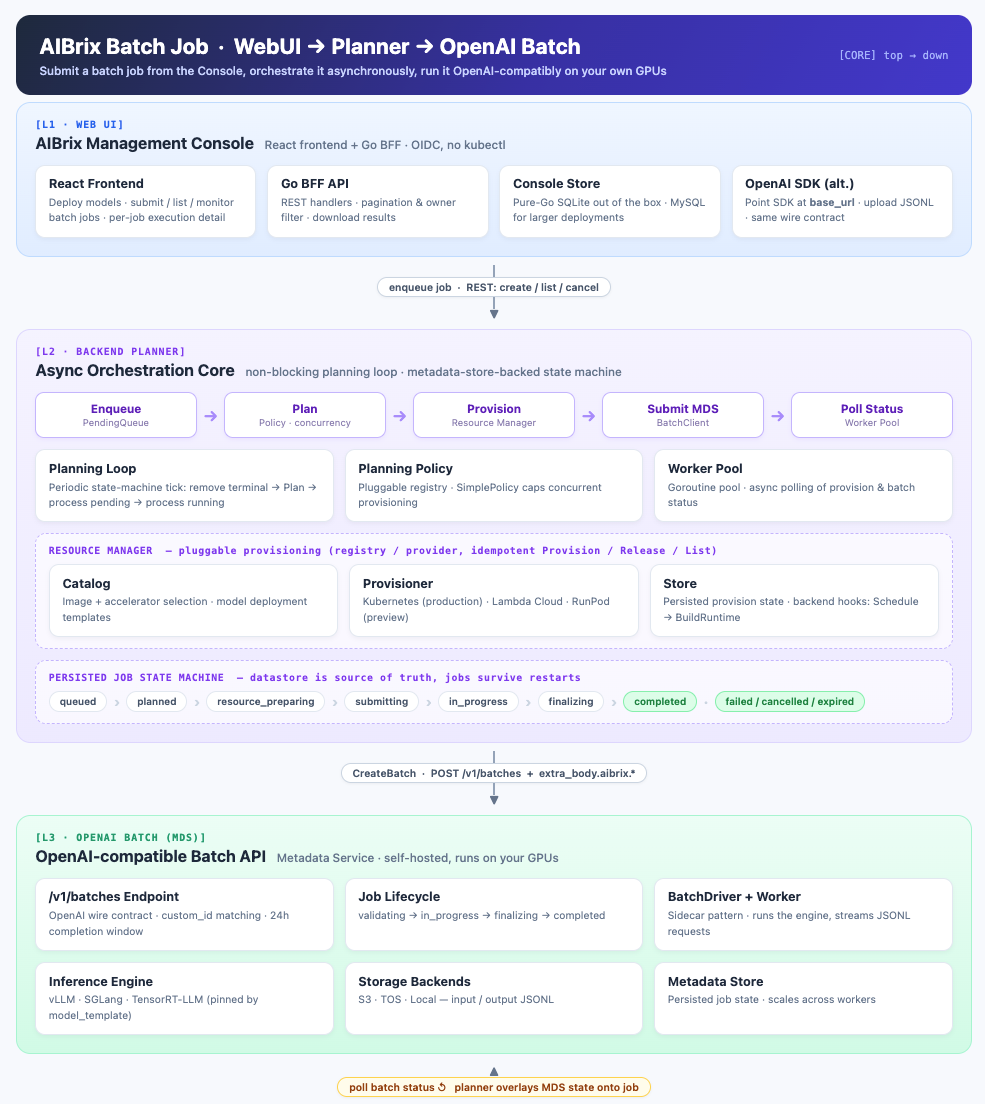 The Batch API Architecture.
The Batch API Architecture.
from openai import OpenAI
client = OpenAI(base_url="http://<aibrix-gateway>/v1", api_key="...")
batch_input = client.files.create(file=open("requests.jsonl", "rb"), purpose="batch")
batch = client.batches.create(
input_file_id=batch_input.id,
endpoint="/v1/chat/completions",
completion_window="24h",
# Optional AIBrix extension — omit it and the job runs on the default template.
extra_body={
"aibrix": {
"job_id": "job_21799a92-6674-42fe-b7d0-fb58f651d9e6",
"runtime": {
"target": "Kubernetes"
},
"resource_allocation": {},
"model_template": {
"name": "L20",
"version": "v1.0.0",
"spec": {
"engine": {
"type": "vllm",
"version": "0.20.0",
"image": "vllm/vllm-openai:latest",
},
"model_source": {
"type": "hdfs",
"uri": "hdfs://..../models/Qwen3.6-27B-Merlin-HF"
},
"accelerator": {
"type": "NVIDIA-L20",
"count": 1,
"vram_gb": 48
},
"parallelism": {
"tp": 1,
"pp": 1,
"dp": 1
},
"quantization": {},
"supported_endpoints": [
"/v1/chat/completions"
],
"deployment_mode": "dedicated"
}
},
"model": "Qwen/Qwen3.6-27B"
}
}
)
Under the hood, AIBrix runs the standard validating → in_progress → finalizing → completed lifecycle with custom_id matching, a 24-hour completion window, and pluggable storage backends (S3, TOS, Redis, or local). Because the datastore — not Kubernetes annotations — is the source of truth, jobs survive restarts and scale across workers.
The optional model_template shown above is the model-centric part: it pins exactly how a given model runs — engine (vLLM, SGLang, or TRT-LLM), model_source, accelerator, parallelism, and quantization — while everything outside the aibrix key stays the standard OpenAI Batch contract, so existing SDKs and tooling keep working. Templates are reusable and versioned (keep a prod and an experimental variant side by side), and the same job can run as an in-cluster Kubernetes Job, on a long-lived Deployment acting as a worker, or — new in v0.7.0, in preview — on rented cloud GPUs (below).
Running batch on cloud GPUs — Lambda Cloud & RunPod (preview)
When your own cluster is full — or you don’t have one — v0.7.0 can run a batch job on rented cloud GPUs. This is powered by a new Resource Manager: a pluggable provisioning layer (registry/provider pattern, idempotent Provision/Release/List) with three providers — Kubernetes, Lambda Cloud, and RunPod (#2248). For an external provider it leases a GPU box, then the batch runtime brings up the engine over SSH and streams your job through it. You target one with a single field in the same model_template from the superset above — set resource.provider to lambda or runpod instead of the default kubernetes, with everything else in the payload unchanged and no SSH, leasing, or provisioning details in the request. From the caller’s side, “run this batch on a rented RunPod box” is one field — the Resource Manager handles leasing, bring-up, and teardown behind it.
Preview — honesty note. The production-honored execution path today is in-cluster Kubernetes. The RunPod and Lambda Cloud runtimes and Resource-Manager providers ship in v0.7.0 and are wired end-to-end, but multi-cloud execution is still rolling out — treat cloud execution as preview, and it’s deliberately scoped to batch / offline workloads, not online serving.
The economics — why run batch on your own GPUs. Batch is where self-hosting pays off most: it’s latency-tolerant, so jobs pack GPUs to high utilization and soak up the idle capacity your online fleet leaves on the table. For workloads where an open model (Qwen, GLM, Kimi, DeepSeek) clears your quality bar, you keep your data in-cluster, pay no per-request fee, and your marginal cost is just the GPUs you already run. On raw token price the cheapest closed batch tiers can be very competitive — but the numbers we publish come from a deliberately basic, un-tuned deployment: a floor we expect to push down with higher batching, quantization, and the KV-reuse and P/D paths in this very release, not a verdict. We map out where the crossover sits — open vs. closed, managed vs. self-hosted, including the much cheaper Chinese-vendor APIs, and how far optimization moves the line — in a companion deep-dive AIBrix Batch Cost Study which comes soon.
Multi-Engine: TensorRT-LLM Joins vLLM and SGLang
One of AIBrix’s oldest community requests was “can it serve more than vLLM?” (#137 in 2024, echoed by #1245 this cycle). v0.7.0 makes TensorRT-LLM a first-class engine alongside vLLM and SGLang. You select the engine per model with a single label, and the gateway interprets each engine’s metrics correctly for routing:
metadata:
labels:
model.aibrix.ai/engine: trtllm # or: vllm, sglang
For TensorRT-LLM specifically, v0.7.0 adds:
- Native engine support and TRT-LLM metrics integration for load- and KV-aware routing (#2000, #2005).
- It’s a first-class engine for disaggregated serving too — gateway end-to-end tests now exercise P/D routing for vLLM, SGLang, and TRT-LLM (#2080).
/v1/completionsprompt_token_idshandling and metrics fixes for production use.
One KV-Cache Data Plane — Offloading and P/D Disaggregation
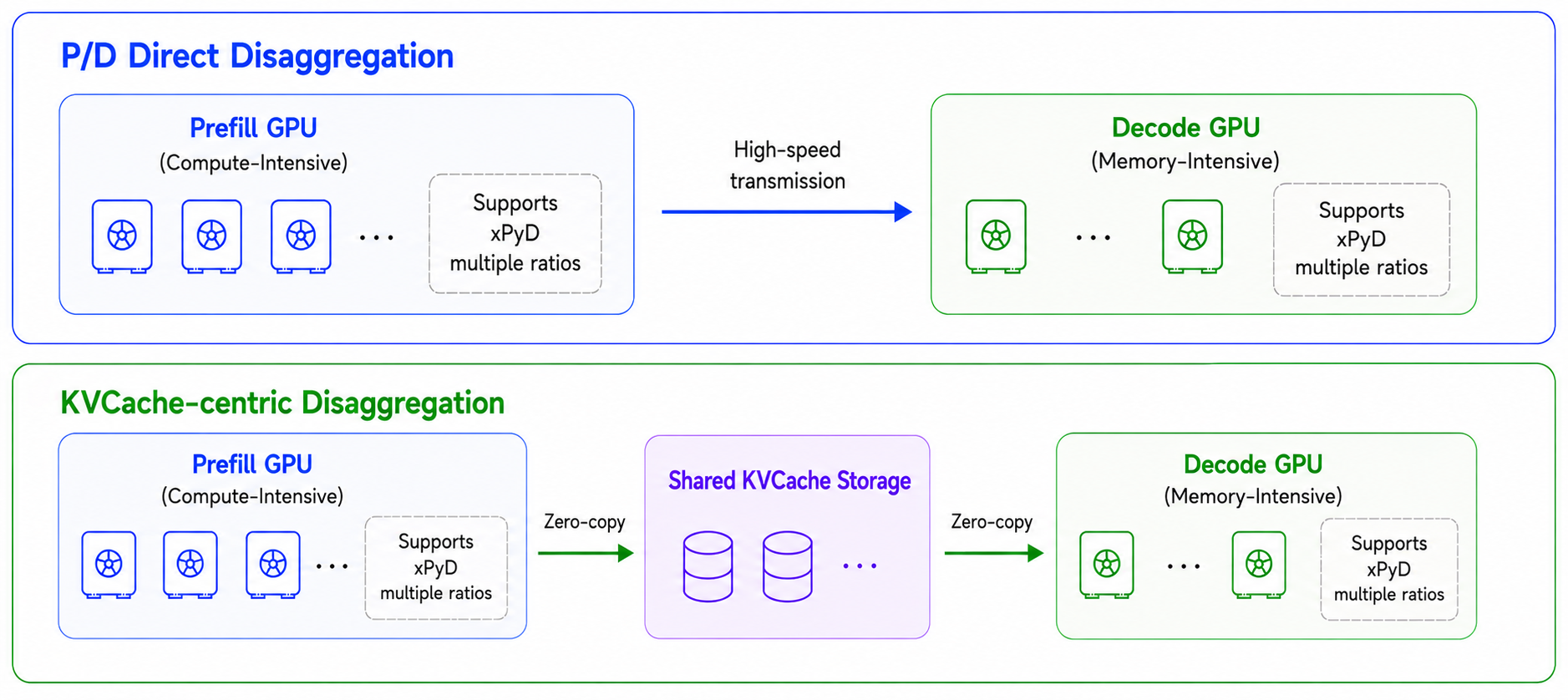
In most stacks, moving the KV cache from a prefill worker to a decode worker is point-to-point transfer (vLLM’s NIXL / P2P-NCCL connectors; SGLang’s RDMA transfer engine), while offloading and reusing KV across requests is a different path (a CPU/disk offload tier, AIBrix KVCache, LMCache, SGLang HiCache). In many default deployments, they’re two separate paths to configure and operate.
Following the KVCache-centric philosophy pioneered by Mooncake, AIBrix routes both through one pluggable KV-cache data plane. The aibrix_kvcache library — L1 DRAM plus a pluggable L2 store (PrisKV in production, with InfiniStore / HPKV / RocksDB as open backends) — is the single substrate behind two connectors:
┌─ P/D transfer — prefill writes KV, decode reads it
aibrix_kvcache ──┤
(L1 + L2 store) └─ offload & reuse — cache KV, reuse it across later requests
- Offloading & reuse —
AIBrixOffloadingConnectormoves KV from GPU to DRAM/L2 and reuses it across requests (cross-engine prefix reuse), with L2 zero-copy APIs (GDRput/get, batched MPUT/MGET) so the offload path stays cheap (#2056). - P/D-disaggregation transfer —
AIBrixPDReuseConnector(#2060, #2092), as illustrated in the following figure, lets a prefill worker write its KV to the store and a decode worker read it. Disaggregation becomes just reuse with a single consumer — no separate point-to-point fabric, and it works single-node, without RDMA, on commodity GPUs like the L20 — validated in our internal testing.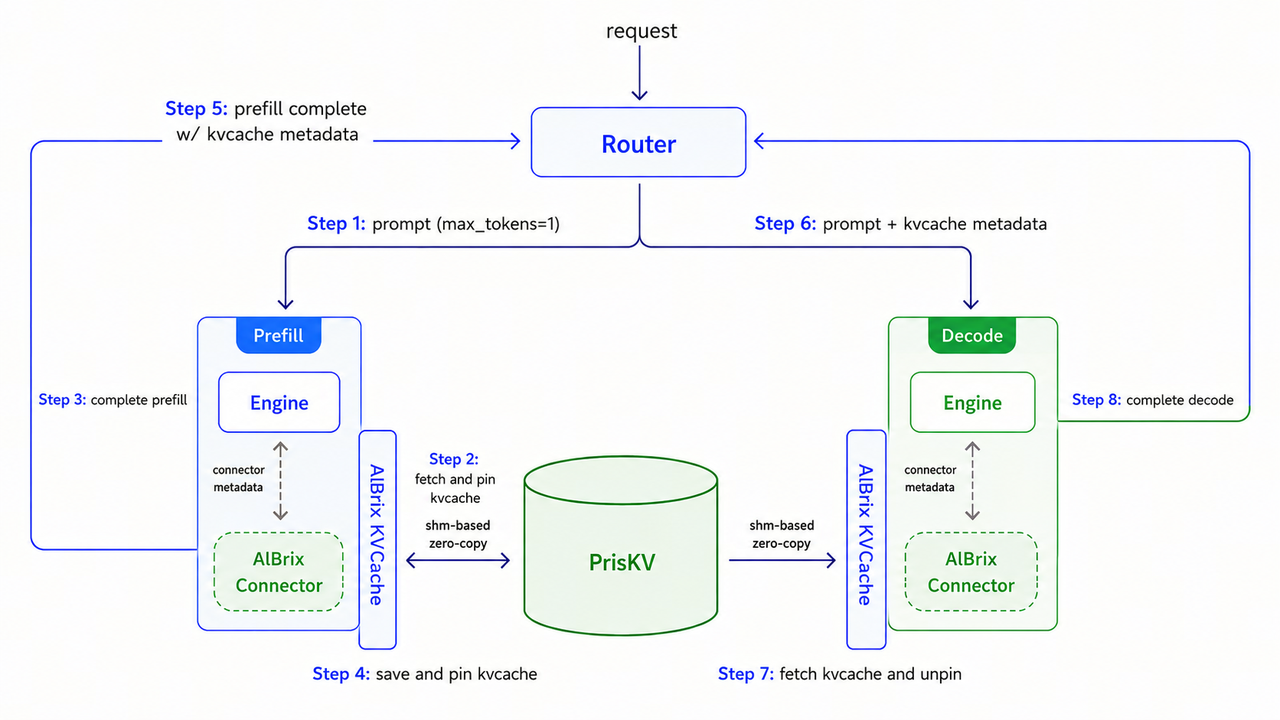
So offloading and disaggregation stop being two separate paths — they become two consumers of the same store-centric KV layer.
According to the performance benchmarks, the KVCache-centric P/D disaggregation approach delivers TTFT gains that scale approximately linearly with KV cache hit rate, and under representative workloads it can reduce first-token latency by around 30%. In multi-turn scenarios, overall throughput can be improved by roughly 2–3× while TPOT remains stable.
Composable Routing & a Highly-Available Gateway
This cycle we advanced AIBrix’s gateway routing on three fronts, in order of impact: refactoring the P/D-disaggregation router into independently pluggable axes, letting you blend routing algorithms instead of picking one, and keeping routing decisions correct once the gateway is replicated for HA.
Routing disaggregated (P/D) traffic. Prefill and decode run on separate pods, so the gateway has to pick a prefill pod, a decode pod, and how their KV cache moves between them. v0.7.0 refactors that P/D router into three independently pluggable axes (#2121, #2284, #2308):
| Axis | Abstraction | Options in v0.7.0 |
|---|---|---|
| Engine orchestration | EngineHandler | vLLM (kv_transfer_params), SGLang (async bootstrap handshake), TensorRT-LLM (disaggregated_params + Snowflake correlation id) |
| KV-transfer connector | KVTransferAgent | SHFS (the AIBrix KV-cache data plane above), NIXL (RDMA / Neuron), Mooncake (stub) — selectable per pod (#2238) |
| Worker-selection policy | PodSelector + scorers | prefill: prefix_cache / least_request; decode: load_balancing / least_request — pluggable via RegisterDecodePolicy |
Each axis moves on its own: add an engine without touching the connectors, swap the KV transport without touching the scorer, register a new selection algorithm without touching either. That last hook is how the upcoming Mooncake Conductor worker-selection algorithm plugs in — as a registered policy, no router surgery.
Composable, multi-strategy routing (#2124, requested by a user in #1843) lets you combine algorithms with weights instead of picking one. Rather than hard-filtering pods, each strategy soft-scores every pod; scores are normalized to [0, 1], weighted, summed, and the top pod wins:
# Blend least-request (weight 2) with throughput (weight 1)
AIBRIX_ROUTING_ALGORITHM="least-request:2,throughput:1"
Omit :weight and it defaults to 1; set it to 0 to disable a strategy; specify an invalid strategy and the gateway returns 400 rather than silently falling back. This avoids routing to extreme outliers that any single metric would chase.
A highly-available gateway needs consistent routing state. Any production gateway runs multiple replicas — that’s what gives you HA and zero-downtime rolling upgrades. But the moment you replicate it, each replica sees only a slice of traffic, so its prefix-cache and load view goes partial and routing quality drops. v0.7.0’s answer is Redis-backed state sharing across replicas. A generic state-sync layer keeps each replica’s prefix-cache hash table consistent (#1989 — pull-then-push with delta sync and TTL tombstones, no PUB/SUB), and per-pod running-request counts are snapshotted across the fleet (#2159). So prefix-cache- and least-request-based routing decisions run on a fresher, fleet-wide view as you scale the gateway out — and you can roll upgrades without sacrificing routing quality.
AIBrix also supports a second route to the same goal — subscribing to the engines’ KV-cache events directly, so each gateway learns the authoritative cached-block state straight from the source rather than via replica-to-replica sync. It requires vLLM KV-event support, a ZMQ-enabled gateway build, a remote tokenizer, and Redis (AIBRIX_PREFIX_CACHE_KV_EVENT_SYNC_ENABLED). We’re actively validating it as an HA path and will share results.
Rounding out routing this cycle: per-model config profiles selectable with a config-profile header (#1944), per-model RPS rate limiting via requestsPerSecond (#2137), a power-of-two-choices router (#2024), and a guide for fronting the fleet with the vLLM Semantic Router as an Envoy ext_proc (#2120).
Other Improvements
- Local mode — Run the AIBrix gateway, router, and KV cache locally against an engine with no cluster, and Redis is now optional (#2039, #2050, #2058). This directly answers the most-discussed support thread in the repo, “how do I run AIBrix on a single server?” (#1690), and lowers the barrier for contributors and benchmarking.
- Anthropic-compatible
/v1/messages— A Messages-format endpoint on the gateway (#2115), broadening client compatibility beyond the OpenAI surface. - OpenTelemetry tracing — Opt-in OTel support wired through the gateway request path (#2255), plus end-to-end trace correlation by preserving the upstream
x-request-id(#2157). - Pluggable service discovery — A generic
Providerinterface decoupling discovery fromv1.Pod, enabling static and (in progress) consul/etcd backends (#2035). - Packaging — External Redis config and component-level password validation in Helm (#2230), CRDs separated from operator manifests (#2222), and GOMAXPROCS tuning to cut futex contention under Kubernetes CPU limits (#2200).
brixbench— a benchmark provisioning harness — A new in-repo benchmark module that provisions a topology, deploys the target version (it can pull released artifacts on demand, so you can A/B currentmainagainst, say, v0.6.0), runs configurable workloads (request-rate, concurrency, num-prompts, dataset, goodput, routing options), and collects metrics. We use it for release validation and regular regression testing — and we’d welcome the community to run it too (#2165, #2273, #2298).
FAQ
Do I have to use the Console now? Can I still drive everything with kubectl and YAML? No — AIBrix remains composable and API-first. The Console is just one surface, on top of the same CRDs and APIs, for people who prefer a UI over the CLI; it’s never a replacement. In v0.7.0 the Batch workflow is the one fully wired in the Console for end-to-end deploy-and-dispatch. Adopt the Console where self-service helps and ignore it where it doesn’t.
How compatible is the Batch API with OpenAI’s Batch API? What do I actually change?
For supported endpoints (/v1/chat/completions, /v1/completions, /v1/embeddings), you change the base_url. The job lifecycle, custom_id matching, file upload, and the 24-hour window follow OpenAI’s contract. A subset of advanced fields is honored today and the rest are deferred with warnings — we document which is which, and the gap is closing release over release.
Why add TensorRT-LLM — and is it production-ready in AIBrix? We added it because users report that, in some scenarios, TensorRT-LLM is faster than vLLM — typically on older, widely-deployed GPUs, where its kernel and operator optimizations can outweigh the newer-hardware focus of engines like vLLM. We haven’t published our own head-to-head benchmarks, so treat this as field-reported rather than a blanket claim; the point is that v0.7.0 lets operators choose the engine that fits their hardware. On readiness: core serving and P/D disaggregation on TRT-LLM are covered by end-to-end tests and ready to evaluate in production; a few items (generation-first P/D scheduling, deeper observability) are tracked for the next cycle, and vLLM and SGLang remain the most battle-tested paths.
The Console is brand new and the Batch API was just overhauled — why ship them now? Because the self-service workflow is the single biggest usability gain in AIBrix’s history, and real usage is how it hardens. We’re explicit about maturity: the Console is new, the Batch API was rebuilt this cycle (it first shipped in v0.5.0), and cloud-GPU execution plus the Resource Manager are preview. None of them change the stability of the core gateway, autoscaler, or KV cache.
Can I run AIBrix on a single machine? Yes. Local mode runs the gateway, router, and KV cache without a cluster, and Redis is now optional (#2039, #2050). It’s the fastest way to try AIBrix or develop against it.
Contributors & Community
This v0.7.0 release includes 242 merged PRs, with 27 from first-time contributors 💫. Thank you to everyone who helped shape this release through code, issues, reviews, and feedback.
We’re excited to welcome the following new contributors to the AIBrix community:
@jasonlee-1024, @Lucas-Qian6, @xvchris, @NJX-njx, @DhyeyTr, @gabrnavarro, @tmchow, @Peakpine, @naroam1, @Yang1032, @DaveLi8086, @Genmin, @ianliuy, @HeyZackWang, @zhutong196, @justinchen033, @Jing-ze, @NelZyhh, @JustAnotherDevv, @xiaoyu-xyz, @arnavnagzirkar, @SarthakB11, @whalepark, @JinKim48, @jan-stanek, @V-3604, @DebugSy 🙌
Your contributions continue to make AIBrix more scalable, production-ready, and welcoming as an open community. We’re excited to see the ecosystem grow—keep them coming!
Beyond the code, the community took real steps toward maturing the project this cycle — a Call for Adopters and discussion of a formal release team and ownership model. Thank you to everyone who filed issues, reviewed PRs, and shipped features.
What’s Next
We’re continuing to push AIBrix toward a fully production-grade, self-service, cloud-native platform — while keeping the stack composable. For v0.8.0, we’re focusing on a few pillars:
- Omni-modal serving — Turn the multimodal foundation into first-class image, audio, and video serving (#1966).
- High-density GPU pooling — Control-plane orchestration of vLLM sleep mode and kvcached for warm-standby, multi-model GPU sharing (#2290).
- Hardening the platform — Graduate the Console, Batch API, and Resource Manager from preview to production, including a deployment provider abstraction (#2198).
If you’re running LLMs in production or exploring architectures around serverless, KV cache, P/D disaggregation, or batch, we’d love your feedback and collaboration. Check out the v0.8.0 roadmap, join the discussion, and contribute on GitHub.