As large language models become widely used in multi-turn conversation, retrieval-augmented generation, and agentic workloads, memory management during inference is emerging as a key bottleneck for both performance and cost. KV cache is one of the core optimizations in LLM serving, and its capacity as well as reuse efficiency directly influences time to first token (TTFT), time per output token (TPOT), and overall system throughput.
This article introduces the AIBrix KVCache approach and presents an optimization strategy for single-node Prefill/Decode (P/D) disaggregation, targeting GPU environments such as NVIDIA L20 where RDMA-capable networking is unavailable. Depending on workload characteristics, the design supports two deployment forms. For workloads where reusable common-prefix demand is limited, a direct P/D disaggregation architecture is sufficient. For workloads such as multi-turn chat, where a substantial fraction of prompts share reusable prefixes, a KVCache-centric P/D disaggregation architecture is more effective.
According to the performance benchmarks, the approach delivers TTFT gains that scale approximately linearly with KV cache hit rate, and under representative real workloads it can reduce first-token latency by around 30%. In multi-turn scenarios, overall throughput can be improved by roughly 2–3× while TPOT remains stable.
Introduction
Large language models generate text by repeatedly using the attention Key and Value tensors produced at earlier steps to predict subsequent tokens. Recomputing those tensors for every new token would introduce prohibitive overhead, so inference systems maintain a temporary memory structure known as KV cache. This cache stores previously generated Key and Value tensors across attention layers and allows the model to reuse them instead of recalculating them, improving both latency and throughput.
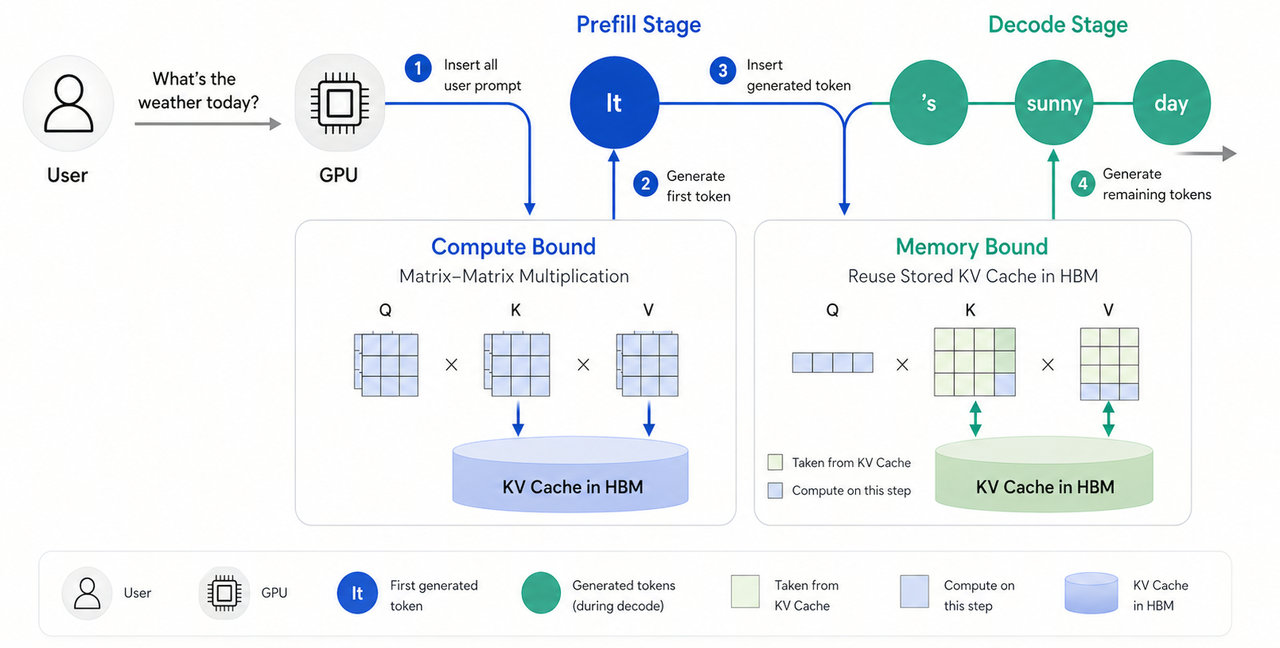
LLM inference can be divided into two core phases. In the Prefill phase, the model processes the entire input prompt in one pass and computes the initial Key-Value pairs, which are then stored in HBM as KV cache. This phase is primarily compute-intensive. In the Decode phase, the model uses the stored KV cache together with the newest generated token to produce the next token. Only the Key-Value pair for the new token needs to be computed and appended to the cache. Decode is therefore relatively lightweight in arithmetic terms, but because it repeatedly reads from HBM, it is mostly memory-access intensive.
KV cache memory usage grows approximately linearly with context length. For mainstream large models, a single token may consume several KB or even MB of KV memory, and one user session can quickly occupy several GB of GPU memory. As model sizes increase and context windows continue to grow, including very long-context models, KV cache pressure becomes a primary bottleneck in inference systems.
The real value of KV cache lies in avoiding redundant computation. When multiple requests share the same input prefix, reusing existing KV cache can substantially reduce Prefill work. This pattern is common in multi-turn chat, RAG, and agentic workflows. In agentic systems, the input-output ratio can be extremely high, which means a large proportion of tokens may be reused from cache [1].
Background and Motivation
KV Cache Offloading
KV cache offloading moves KV cache from limited GPU memory into larger and lower-cost storage layers such as CPU memory, SSD, or remote storage. This makes it possible to go beyond raw GPU-memory limits.
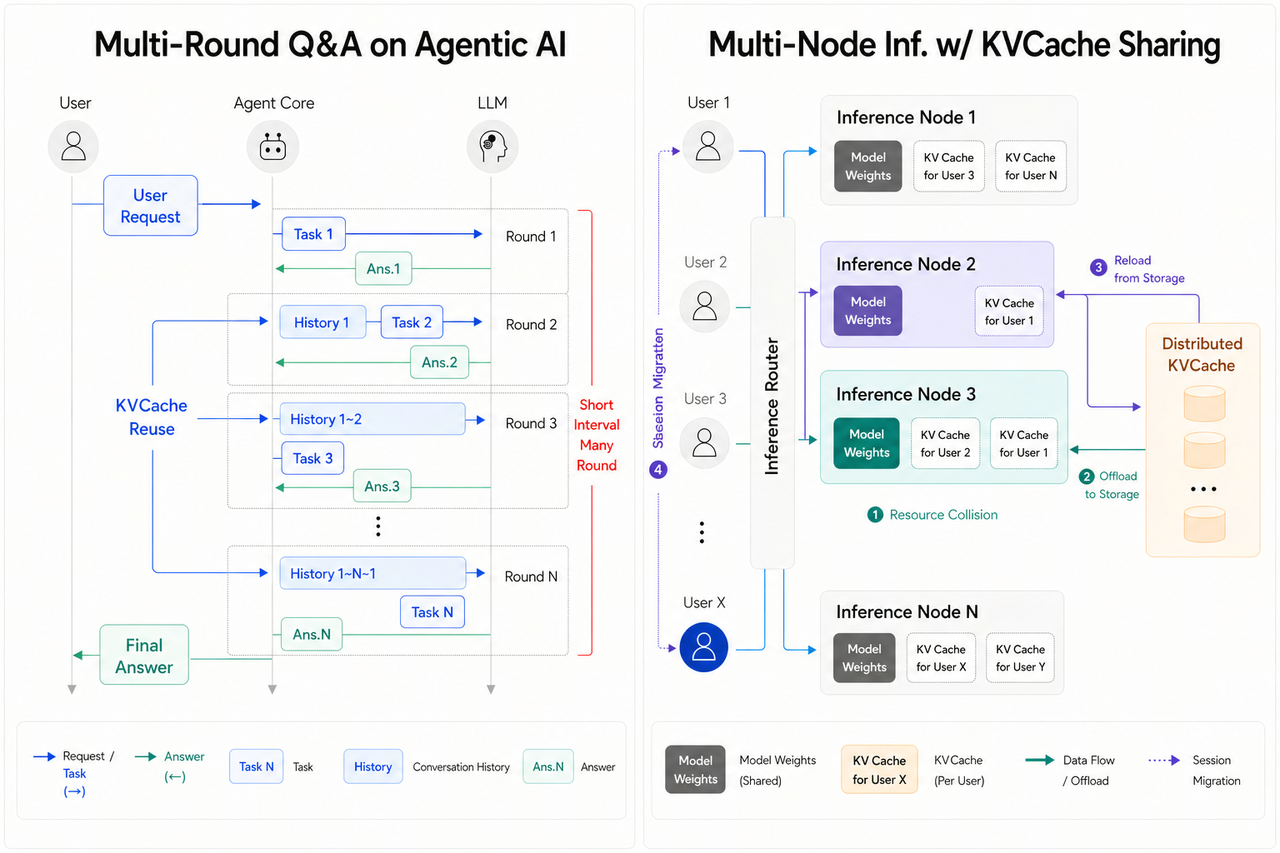
In agentic AI workflows, the agent core and the LLM repeatedly interact across multiple turns: parsing intent, generating plans, retrieving information, integrating results, and iterating until the user goal is satisfied. Because variations of the same prompt are processed again and again, repeated Prefill becomes increasingly inefficient as the prompt grows. Reusing KV cache from previous turns helps avoid that redundant work and keeps latency under control during long reasoning chains.
In multi-node clusters, workloads may migrate across GPUs because of load balancing, elastic resource allocation, or failure recovery. When sessions migrate, local KV cache is lost and must be rebuilt, which adds significant delay. Externalizing the cache allows it to be reloaded after migration and helps maintain execution continuity. In dynamic inference environments, KV cache offloading is therefore not just a performance optimization but a systems mechanism for stable latency, predictable throughput, and scalable serving.
Capacity expansion: supports longer context windows and higher concurrency.
Cross-instance reuse: enables KV cache sharing across distributed environments.
Persistence: supports pause, resume, and migration scenarios.
Mobility: preserves continuity when workloads move across serving instances.
Public industry results also suggest substantial benefits from KV cache offloading, including major TTFT improvements, speedups for long-prompt workloads, and significant throughput gains in multi-turn scenarios [2] [3] [4].
The Evolution of P/D Disaggregation
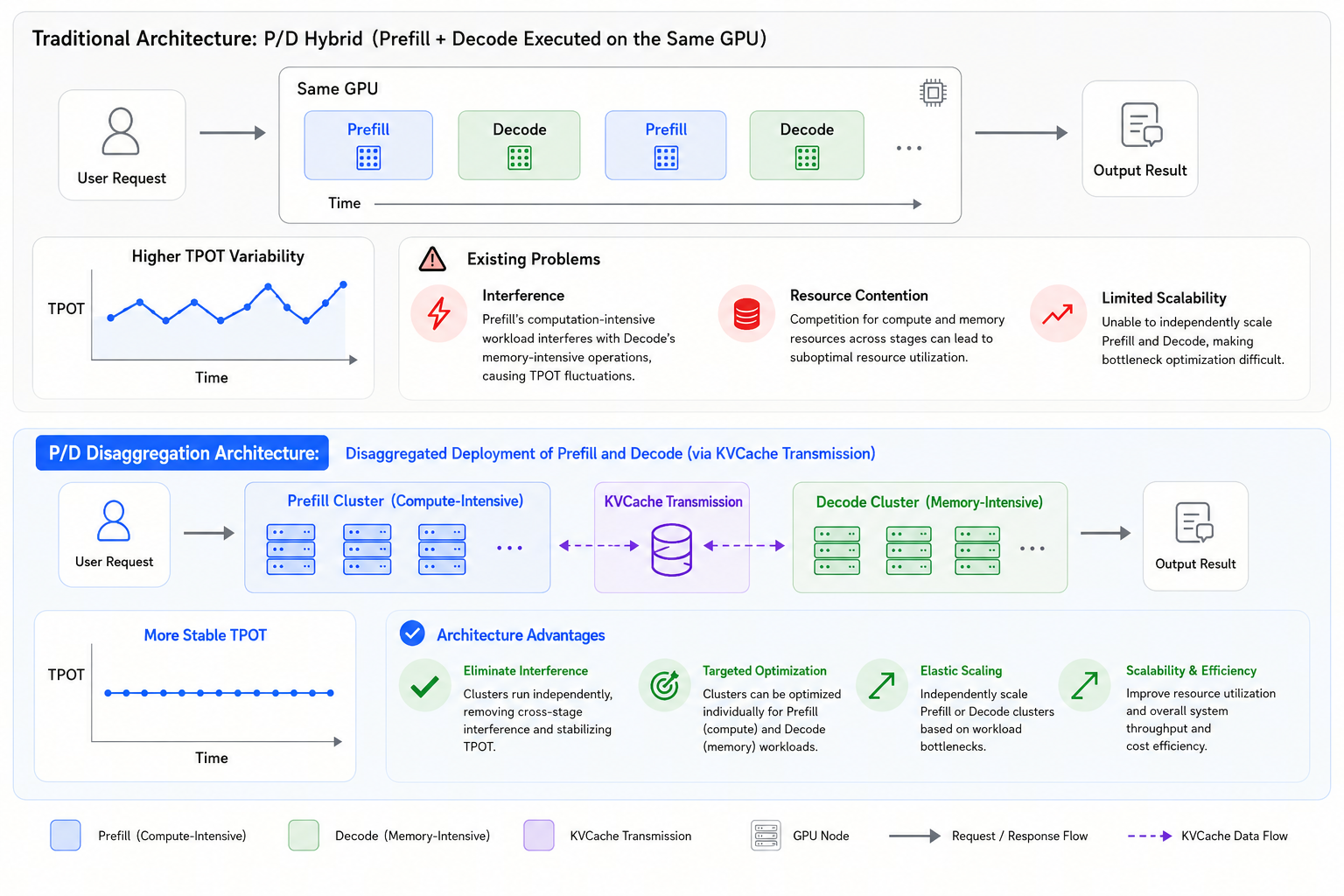 Traditional inference often mixes Prefill and Decode on the same GPU. This mixed deployment creates several issues. First, compute-intensive Prefill can interfere with the memory-intensive Decode path, causing TPOT fluctuation. Second, the two phases compete for resources even though their hardware bottlenecks differ significantly. Third, the architecture limits targeted optimization because Prefill and Decode cannot be tuned or scaled independently.
Traditional inference often mixes Prefill and Decode on the same GPU. This mixed deployment creates several issues. First, compute-intensive Prefill can interfere with the memory-intensive Decode path, causing TPOT fluctuation. Second, the two phases compete for resources even though their hardware bottlenecks differ significantly. Third, the architecture limits targeted optimization because Prefill and Decode cannot be tuned or scaled independently.
P/D disaggregation addresses this by decoupling Prefill and Decode onto different GPUs and using KV cache to pass context between them. This separation removes phase interference, allows phase-specific optimization, and enables independent scaling for Prefill and Decode.
Workload Scenarios and Challenges
Many real production workloads share several common characteristics: long multi-turn histories, reusable common prefixes such as system prompts or domain documents, strict latency requirements, and spikes in concurrent traffic.
At the same time, many deployments on NVIDIA L20-class hardware face practical limitations: the absence of RDMA high-speed networking, the absence of NVLink, and relatively limited HBM capacity. These constraints make cross-node P/D disaggregation less attractive and make single-node optimization especially important.
Many extensive explorations and engineering optimizations have been conducted to overcome the various limitations of the L20 platform and unlock greater performance and cost efficiency in production deployments. For example, a multi-node Prefill/Decode (P/D) disaggregated deployment has been evaluated using the Qwen3-32B-FP8 model with the vLLM v0.11.0 engine in a TP4 configuration. The experiments showed that, because most L20 deployments lack RDMA-capable high-speed networking, cross-node KVCache transfer becomes a significant bottleneck. As a result, the Time to First Token (TTFT) reached 11,494 ms, far exceeding the 1,500 ms achieved by the single-node colocated deployment and failing to satisfy the service SLO.
In contrast, the single-node P/D disaggregation deployment demonstrated substantial benefits in production. With the same total GPU count and unchanged P99 end-to-end latency, system throughput (QPS) increased by more than 40%. Alternatively, while maintaining the same QPS and P99 latency, GPU usage could be reduced by more than 40%, saving approximately 1,600 L20 GPUs during peak hours and around 1,000 L20 GPUs on a daily weighted average. These results clearly demonstrate that single-node P/D disaggregation is a significantly more cost-efficient deployment strategy than traditional colocated P/D execution on L20 platforms.
Nevertheless, due to the hardware limitations of the L20 platform, application-specific workload characteristics, and strict SLO requirements, production deployments still face several fundamental challenges.
Challenge 1: Poor Adaptability of Native Inference Engines to the L20 Platform
Lack of optimized quantization configurations. Mainstream inference engines (e.g., vLLM) do not provide quantization configurations specifically optimized for the L20 architecture. As a result, when deploying quantized models such as FP8 or INT8, the hardware capabilities of the L20 cannot be fully utilized, leading to significantly degraded inference performance and preventing the system from achieving its theoretical acceleration potential.
Incorrect transport protocol selection. In single-node P/D disaggregation scenarios on L20, the vLLM NIXL connector incorrectly uses TCP for KVCache transmission. This introduces excessive KVCache transfer latency, dramatically increases TTFT, and makes it impossible to satisfy production SLO requirements.
Challenge 2: Conventional P/D Disaggregation Cannot Provide Large-Scale KVCache Reuse
The L20 is equipped with only 48 GB of HBM, imposing a strict upper bound on available GPU memory. Even with prefix caching enabled, existing inference engines can cache only a small number of reusable prefixes. This limitation becomes particularly severe in the following scenarios:
Multi-turn conversations: The reusable prefix (system prompt plus conversation history) for a single session may contain thousands of tokens and consume tens of gigabytes of memory.
Multi-tenant deployments: Multiple tenants may share identical system prompts and knowledge bases, requiring a large number of reusable prefixes to be cached simultaneously.
High-concurrency workloads: A large number of active sessions causes prefix caches to be frequently evicted.
As a result, conventional approaches are fundamentally constrained by HBM capacity and cannot cache a sufficiently large set of reusable prefixes. Many common prefixes must therefore be repeatedly prefilled for every request, resulting in substantial and unnecessary compute overhead.
Challenge 3: Cache Inconsistency Across Multiple Prefill Instances
In deployment topologies such as single-node 3P1D with multiple Prefill instances, each Prefill instance maintains an independent Prefix Cache with a different cache state. To ensure that follow-up requests from the same session can reuse previously generated KVCache, requests must be carefully routed to the appropriate Prefill instance. This introduces two major challenges:
High scheduling complexity. The scheduler must maintain explicit mappings between sessions and Prefill instances, significantly increasing scheduling complexity.
Load imbalance. Cache affinity constraints may overload certain Prefill instances while leaving others underutilized, resulting in poor resource utilization.
To address these L20-specific challenges in a systematic manner, we propose the AIBrix KVCache architecture.
AIBrix KVCache Architecture
AIBrix KVCache is presented as a KV cache management framework for open-source inference engines such as vLLM and SGLang. The design provides two complementary deployment modes and allows operators to choose between them based on workload behavior and hardware conditions.
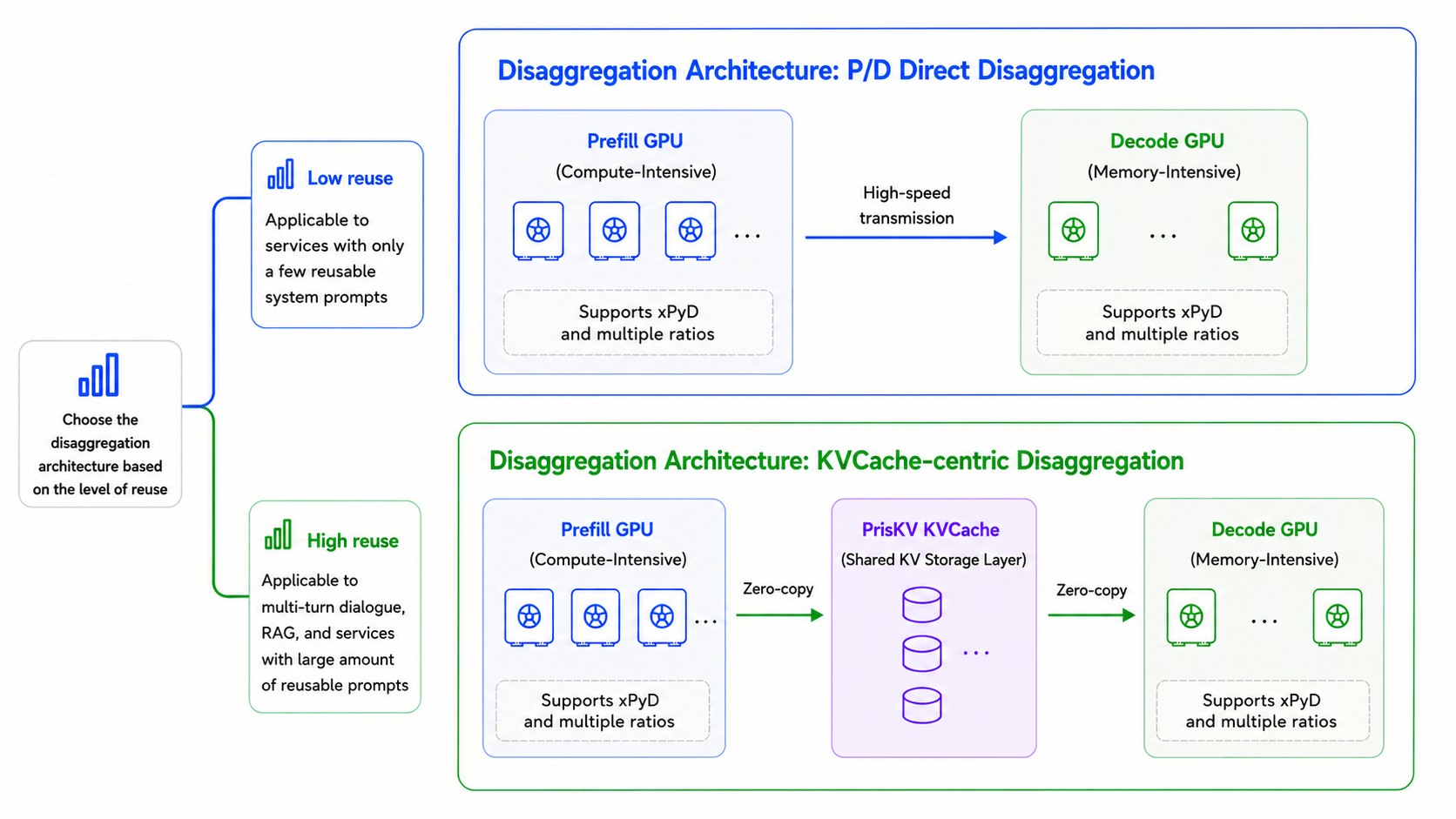
Form 1: P/D Direct Disaggregation
This form is suitable when the reusable common-prefix ratio is low or when the number of reusable prefixes is small enough that the engine’s HBM-based prefix cache can already hold them. In this mode, the main goal is not large-scale cache expansion but efficient intra-node KV transfer and clean separation between Prefill and Decode.
This mode mainly addresses poor native-engine adaptation on L20-like hardware. When the engine uses an inefficient transfer path, the AIBrix approach replaces that path with a more efficient intra-node transport mechanism for KV transfer, thereby avoiding unnecessary TTFT inflation.
Form 2: KVCache-Centric P/D Disaggregation
This form is intended for workloads where reusable prefixes matter, including multi-turn dialogue, RAG, and agentic workflows, and where throughput and cost efficiency are major priorities.
The AIBrix KVCache-centric P/D disaggregation architecture adopts PrisKV as the intra-node data-plane hub, providing unified management and high-performance transport for KVCache in P/D-disaggregated deployments.
PrisKV is a hierarchical KVCache storage system purpose-built for LLM inference services (see the PrisKV Blog for details). It provides a zero-copy data path, full-stack communication support across TCP, shared memory, and RDMA, as well as comprehensive KVCache lifecycle management. Its primary objective is to preserve the benefits of P/D disaggregation while enabling cross-request KVCache reuse and decoupling the data-path dependency between Prefill and Decode engine instances.
Built upon KVCache offloading, this architecture primarily addresses the challenges of limited HBM capacity and cache inconsistency across multiple Prefill instances. By extending the lifetime of KVCache through offloading, it enables cross-engine and cross-request reuse, transforming the traditional compute-for-memory tradeoff into a memory-for-compute strategy and effectively overcoming the capacity limitations of on-device HBM. In addition, by introducing a centralized KVCache layer with a unified cache view, the architecture eliminates cache inconsistency across multiple Prefill instances and simplifies request scheduling.
KVCache-Centric Request Flow
In the single-node L20 P/D disaggregation architecture, each request is processed according to the workflow illustrated in the figure.
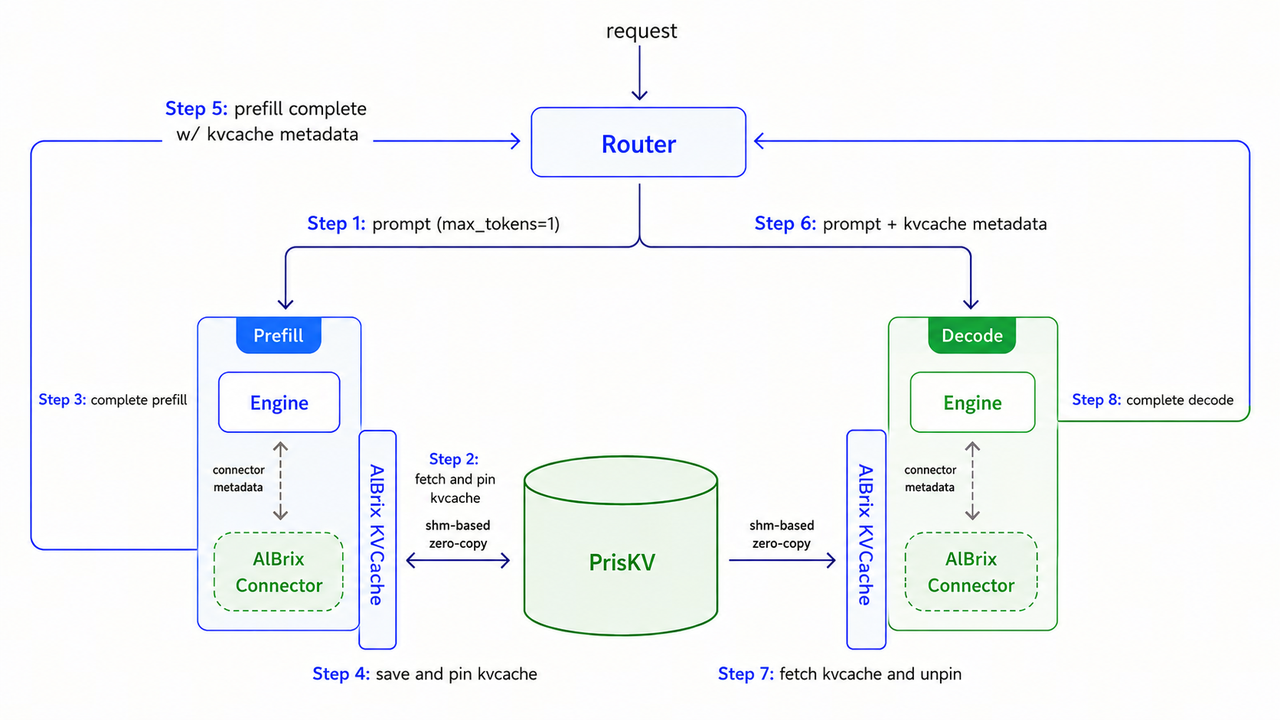
First, the Router dispatches the Prefill request to a Prefill instance. The Prefill instance queries PrisKV for reusable KVCache entries. If a cache hit occurs, the corresponding KVCache is pinned and its metadata is returned. The Prefill instance then performs Prefill computation only for the cache-miss portion of the prompt, generating KVCache for the newly processed tokens.
The newly generated KVCache is subsequently written back to PrisKV and pinned to prevent premature eviction. Afterward, the Prefill instance returns the complete KVCache metadata to the Router. The Router then forwards the Decode request, together with the associated KVCache metadata, to a Decode instance.
Upon receiving the request, the Decode instance retrieves the required KVCache from PrisKV and performs an unpin operation after the KVCache has been successfully loaded into HBM. Finally, the Decode computation is executed to generate the output tokens.
Throughout the entire request lifecycle, PrisKV provides centralized KVCache management and lifecycle control, enabling efficient KVCache reuse across requests while decoupling the Prefill and Decode execution paths.
KV Cache Reuse Mechanism
The foundation of KVCache reuse is efficient prefix matching. AIBrix implements high-performance prefix matching through a block-based indexing mechanism built on recursive hashing.
Specifically, the KVCache is partitioned into fixed-size blocks (e.g., 256 tokens per block), and a recursive hash is computed for each block to serve as its unique identifier. A prefix-tree (trie) index is then maintained to map token sequences to their corresponding recursive block hashes, enabling efficient prefix lookup.
When a new request arrives, the system uses the trie index to quickly identify reusable KVCache blocks. The matched KVCache blocks are fetched from PrisKV and loaded into GPU HBM, while Prefill computation is performed only for the cache-miss portion of the prompt. This design minimizes redundant computation and enables efficient KVCache reuse across requests.
Zero-Copy Transfer
In conventional KVCache-centric P/D disaggregation architectures, KVCache offloading and transfer involve multiple memory-copy operations along the data path:
GPU HBM (Prefill Engine) → CPU Memory (Prefill Engine) → Network → CPU Memory (KVCache Service) → Network → CPU Memory (Decode Engine) → GPU HBM (Decode Engine)
Each additional memory copy introduces unnecessary latency and degrades end-to-end performance.
AIBrix eliminates these redundant copies through a zero-copy data path, reducing the transfer pipeline to:
GPU HBM (Prefill) → CPU DRAM (PrisKV) → GPU HBM (Decode)
This optimization is enabled by two key technologies:
Shared memory mapping. The Prefill process, Decode process, and PrisKV share the same physical memory region through shared-memory mapping, eliminating redundant CPU-side memory copies and enabling direct access to KVCache data.
Specialized transfer kernels. Optimized CUDA kernels are used to perform high-throughput, low-latency KVCache transfers between GPU HBM and CPU DRAM, minimizing transfer overhead while maximizing hardware utilization.
By removing unnecessary intermediate copies and streamlining the data path, AIBrix significantly reduces KVCache transfer latency and improves the efficiency of KVCache-centric P/D disaggregation on L20 platforms.
Shared State Across Multiple Prefill Instances
In deployment shapes such as 3P1D, the architecture allows multiple Prefill instances to share a unified cache view through the centralized cache layer. That means the external scheduler can treat those Prefill workers as one logical cache domain instead of maintaining fine-grained session affinity for each individual worker. This reduces routing complexity and improves the practical value of cache reuse.
Performance Evaluation
Experimental Setup
| Configuration | Value |
|---|---|
| GPU | NVIDIA L20 (48 GB HBM) |
| Model | Qwen3-32B-FP8 |
| Deployment form | Single-node 1P1D (TP=4), 3P1D (TP=2) |
| Engine | vLLM v0.11.0 |
Random-Load Benchmark
Test Configuration.
The evaluation was conducted using the Qwen3-32B-FP8 model in a single-node 1P1D setup with TP=4. The workload configuration was as follows: input_len=6000, output_len=80, concurrency=2, and RPS=16.
We used the random workload generated by the vLLM benchmark tool to compare performance under different KVCache hit ratios.
| KVCache Hit Ratio | TTFT (ms) | TPOT (ms) | TTFT Improvement (%) |
|---|---|---|---|
| baseline (no reuse) | 1564.68 | 19.75 | - |
| 0% | 1585.25 | 18.17 | -1.31% |
| 10% | 1468.18 | 18.69 | 6.17% |
| 20% | 1362.35 | 18.78 | 12.93% |
| 30% | 1223.54 | 18.92 | 21.80% |
| 40% | 1060.78 | 19.01 | 32.20% |
| 50% | 931.00 | 19.12 | 40.50% |
| 60% | 805.04 | 19.22 | 48.55% |
Key Findings.
Near-linear improvement. TTFT improves approximately linearly as the KVCache hit ratio increases.
Significant TTFT reduction at 60% hit ratio. When the KVCache hit ratio reaches 60%, TTFT decreases from approximately 1,550 ms to around 800 ms, representing an improvement of about 48%.
Stable TPOT. TPOT remains stable across different hit ratios, staying around 18–19 ms. This indicates that KVCache reuse does not introduce additional overhead during the decode phase.
Negligible architectural overhead. Even at a 0% KVCache hit ratio, both TTFT and TPOT remain comparable to the baseline, demonstrating that the architecture introduces only well-controlled overhead.
For a representative production workload, the common-prefix ratio is around 37%, which falls within the 30–40% range. Under this workload, TTFT can be reduced by approximately 500 ms, corresponding to an improvement of around 30%.
NVIDIA AIPerf Benchmark
We used NVIDIA AIPerf User-Centric Timing for standardized evaluation. AIPerf User-Centric Timing is specifically designed for KVCache benchmarking. In this mode, the time interval between user turns in multi-turn conversations is precisely controlled as turn_gap = num_users / QPS, and the request timeline of each user is scheduled independently.
The prompt is structured into three layers:
Shared System Prompt: shared by all users to evaluate reusable prefix caching.
User Context Prompt: unique to each user, simulating per-user conversation history.
Per-Turn Input: newly generated input for each conversation turn.
In this experiment, the E2E latency SLO was set to approximately 5 seconds. We compared the maximum throughput (RPS) that different schemes can sustain while satisfying the same latency constraint. Under the same production traffic, higher throughput means that each GPU can serve more requests, thereby reducing the number of GPUs required. Based on the experimental results, we further quantify the throughput speedup of each scheme relative to the baseline and estimate the corresponding GPU resource savings under the same workload.
Test Configuration.
We used NVIDIA AIPerf User-Centric Timing to simulate a multi-turn conversation workload. The configuration was as follows: 10 concurrent users (--num-users 10), an average of 4 conversation turns per user (--session-turns-mean 4), a 3,000-token shared system prompt (--shared-system-prompt-length 3000), a 6,000-token user context prompt (--user-context-prompt-length 6000), 256 tokens of per-turn input (--synthetic-input-tokens-mean 256), and an output length of 80 tokens (--osl 80). The model was Qwen3-32B-FP8. The AIBrix deployment used a 3P1D topology with random routing, while the baseline deployment used four replicas with random routing.
| Scheme / Configuration | Avg. TTFT (ms) | Avg. TPOT (ms) | Avg. E2E Latency (ms) | RPS (req/s) | Speedup |
|---|---|---|---|---|---|
| Baseline: 4 replicas w/o prefix-cache | 2882.52 | 31.15 | 5205.23 | 0.50 | 1.00 |
| Baseline: 4 replicas w/ prefix-cache | 2338.70 | 168.01 | 5193.56 | 0.79 | 1.58 |
| AIBrix Form 1: 3P1D w/ prefix-cache | 2108.81 | 37.47 | 5068.13 | 1.38 | 2.76 |
| AIBrix Form 2: 3P1D w/o prefix-cache | 1580.98 | 40.36 | 4983.35 | 1.35 | 2.70 |
| AIBrix Form 2: 3P1D w/ prefix-cache | 2190.79 | 35.87 | 5071.72 | 1.55 | 3.10 |
Note that the native vLLM + NIXL connector 3P1D configuration cannot satisfy the 5-second E2E latency SLO under this experimental setup, regardless of whether engine-level prefix-cache is enabled.
The results show that AIBrix significantly outperforms the baseline across overall performance metrics. The baseline achieves at most 0.79 RPS, even with prefix-cache enabled, whereas AIBrix sustains more than 1.35 RPS across all tested configurations and reaches up to 1.55 RPS, delivering approximately 2–3× higher throughput.
In terms of latency, AIBrix also achieves substantially lower TTFT, with the best configuration reducing TTFT to 1,581 ms compared with 2,883 ms for the baseline. E2E latency is also slightly improved, remaining around 5.0 seconds compared with approximately 5.2 seconds for the baseline.
Meanwhile, TPOT remains stable in the 35–40 ms range for AIBrix. In contrast, the baseline with prefix-cache enabled shows a significant TPOT increase to 168 ms, indicating amplified contention between Prefill and Decode execution. Overall, AIBrix provides clear advantages over the baseline in throughput, first-token latency, and runtime stability.
Typical Scenarios
| Scenario | Workload Characteristics | Recommended Deployment |
|---|---|---|
| Limited System Prompt Scenarios | A small set of fixed system prompts (typically 3–5 prompts with a combined length of approximately 5,000 tokens) serving high-concurrency requests. | Form 1 |
| Intelligent Customer Service (Multi-turn Conversations) | Multi-turn conversations with a System Prompt + FAQ of approximately 2,000 tokens, while each dialogue turn contributes an additional ~256 tokens of accumulated context. | Form 2 |
| Agentic Workflows | Tool definitions and historical context totaling approximately 4,000 tokens, with the model generating code or natural language responses. | Form 2 |
| RAG-based Document Question Answering | Retrieved documents combined with user queries, where the retrieved document context is approximately 10,000 tokens in length. | Form 2 |
| Long-lived Persistent Sessions | User sessions accumulate up to 128,000 tokens of context and may be suspended and later reactivated while preserving conversation history. | Form 2 |
| High-Concurrency, Resource-Constrained Deployments | Traffic surges (e.g., during major promotional events) lead to extremely high request concurrency and severe GPU memory pressure. | Form 2 |
In general, Form 1 is best suited for workloads with a small number of highly reusable shared prefixes, where maximizing reuse of common system prompts provides the greatest benefit. Form 2 is designed for workloads with large or user-specific contexts, enabling efficient KVCache offloading and cross-request reuse to overcome HBM capacity limitations and improve overall system throughput.
References
[1] Context Engineering for AI Agents: Lessons from Building Manus
[2] NVIDIA Dynamo + VAST = Scalable, Optimized Inference