AIBrix is a composable, cloud‑native LLM inference infrastructure designed to deliver high performance and low cost at scale. We now present a major update in a new release - v0.4.0. This release tackles key bottlenecks in orchestration and routing for Prefill/Decode(P/D) Disaggregation and Large‑scale Expert Parallelism(EP), optimizations in the AIBrix KVCache V1 Connector, KV Event synchronization from engine and Multi‑Engine support.
v0.4.0 Highlight Features
StormService for Prefill/Decode (P/D) Orchestration and P/D‑Aware Routing Support
P/D disaggregation is an architecture where the prefill (forward computation) and decode (token generation) phases run on different GPU nodes to improve resource utilization and throughput. To support P/D disaggregation, AIBrix defines a custom resource called StormService that manages the life‑cycle of inference containers in a P/D architecture. StormService uses a three‑layer structure: a top‑level StormService object encapsulates the service and tracks replica count; a middle‑level RoleSet represents a group of roles (such as Prefill or Decode); and the bottom‑level Pod performs the actual inference tasks. This hierarchical design allows updates to propagate from StormService downwards, and each level’s reconciler synchronizes status as needed, enabling atomic scale‑up/down and rolling updates for P/D services.
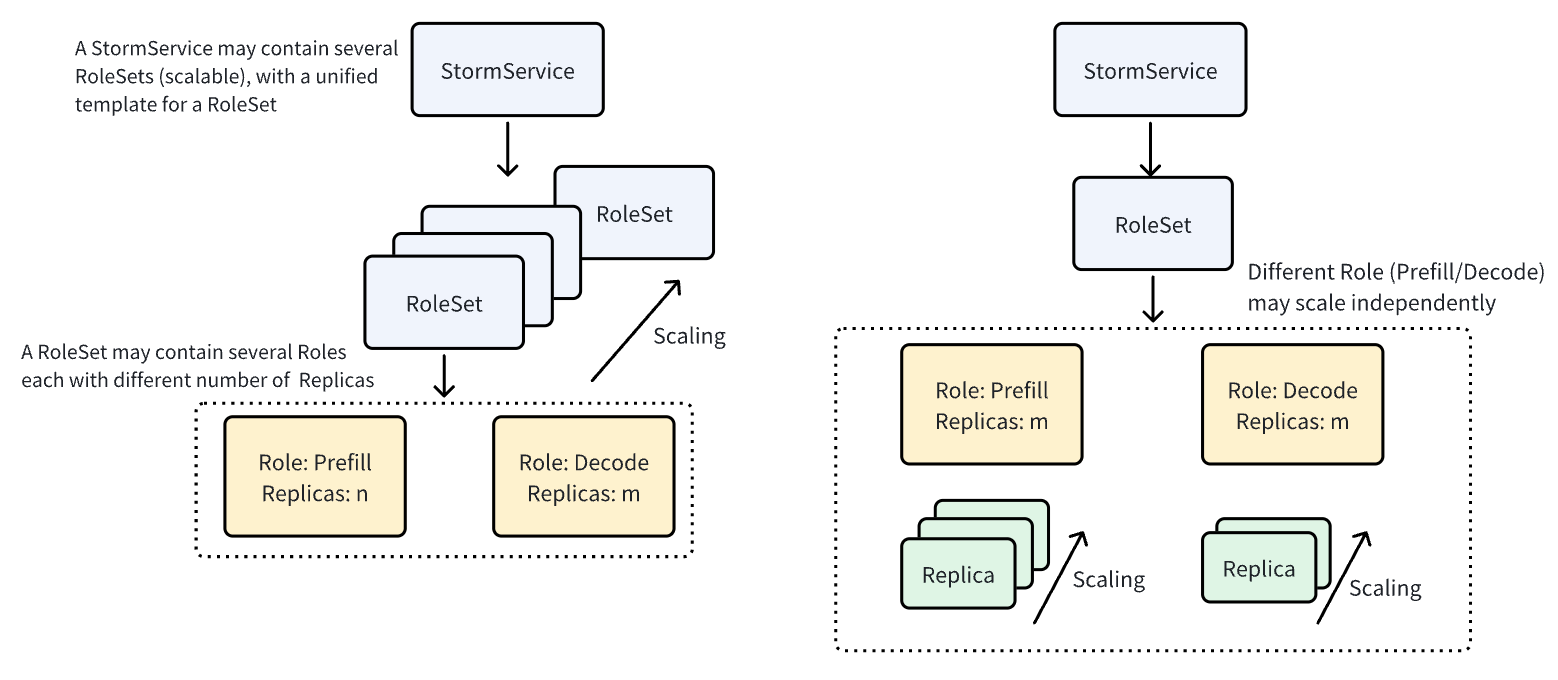
StormService supports two deployment modes—replica mode and pooled mode—to accommodate different prefill/decode (P/D) scenarios. For updates, StormService offers two strategies: Replica mode supports Rolling Update, which gradually replaces old RoleSets with new ones, while Pooled mode supports InPlace Update to directly update existing RoleSets without consuming extra GPUs during the process. To further control upgrade behavior in multi-role deployments, StormService also supports sequential, parallel, and interleaved rolling strategies.
With P/D disaggregation in place at the infrastructure level, routing becomes the next critical step to ensure efficient request handling during runtime. In the P/D routing workflow, the AIBrix Gateway Plugin begins by selecting a prefill worker. This selection is made using prefix-cache awareness to optimize for cache hits and ensure effective load balancing across available workers. Once a prefill worker is chosen, the plugin sends the prefill request directly to that worker. The handling of the prefill request depends on the underlying inference engine:
- For vLLM, the request to the prefill worker is synchronous. Upon successful completion, the process proceeds to the decode phase.
- For SGLang, the request is handled asynchronously, allowing the system to continue without waiting for an immediate response.
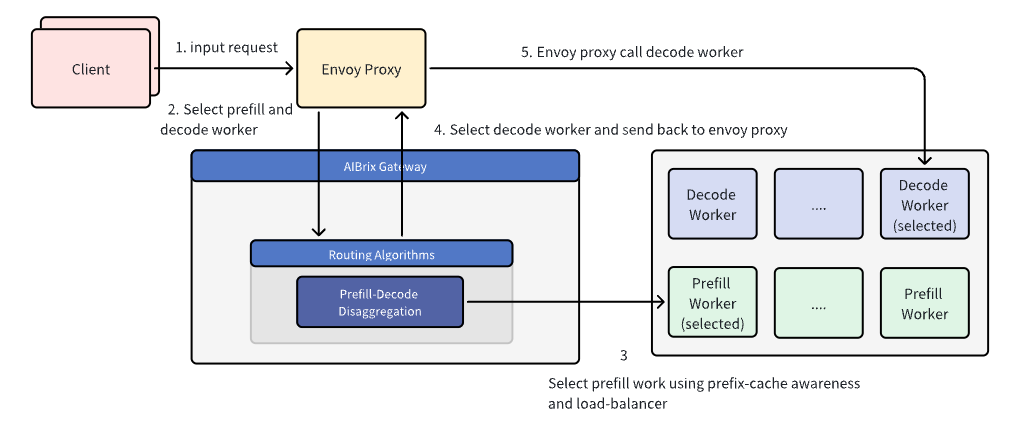
After the prefill step is complete, a decode worker is selected. In the current implementation, the decode worker is chosen randomly. However, future enhancements aim to optimize this selection by considering factors such as KV cache transfer latency and worker load to improve efficiency. The connection details of the selected decode worker are then returned to the Envoy proxy, which forwards the decode request accordingly. The subsequent propagation and response-handling mechanism from the Envoy proxy to the decode worker remains unchanged. The key distinction in this workflow lies in the special handling of the prefill request, which introduces a dedicated step to route and process prefill separately before proceeding to decode.
The following figures illustrate the benefits of prefix-aware routing enabled by AIBrix’s PD-aware routing support. To evaluate the impact of this feature, we design two workloads inspired by real-world scenarios. The prefix-sharing workload simulates requests that share a few long common prefixes, mimicking scenarios with significant prefix overlap (as described in our benchmark setting). The exact sharing patterns used are specified below. The multiturn workload simulates a multi-turn conversation, with a mean request length of 2,000 tokens (standard deviation: 500) and an average of 3.55 turns per conversation.
Experiments are conducted on NVIDIA H20 GPUs under two configurations: (1) 2P1D using the Qwen/Qwen3-8b model, and (2) 2P2D with tensor parallelism (TP = 2) using the Qwen/Qwen3-32b model.
Our results show that AIBrix, when integrated with vLLM(v0.9.2), significantly improves both median and tail Time-to-First-Token (TTFT) across both workloads. For the Qwen/Qwen3-8b model, AIBrix achieves up to 72% improvement in median TTFT and 7% in 95th percentile TTFT. For the larger Qwen/Qwen3-32b model, AIBrix improves median TTFT by up to 44% and tail TTFT by up to 31%.
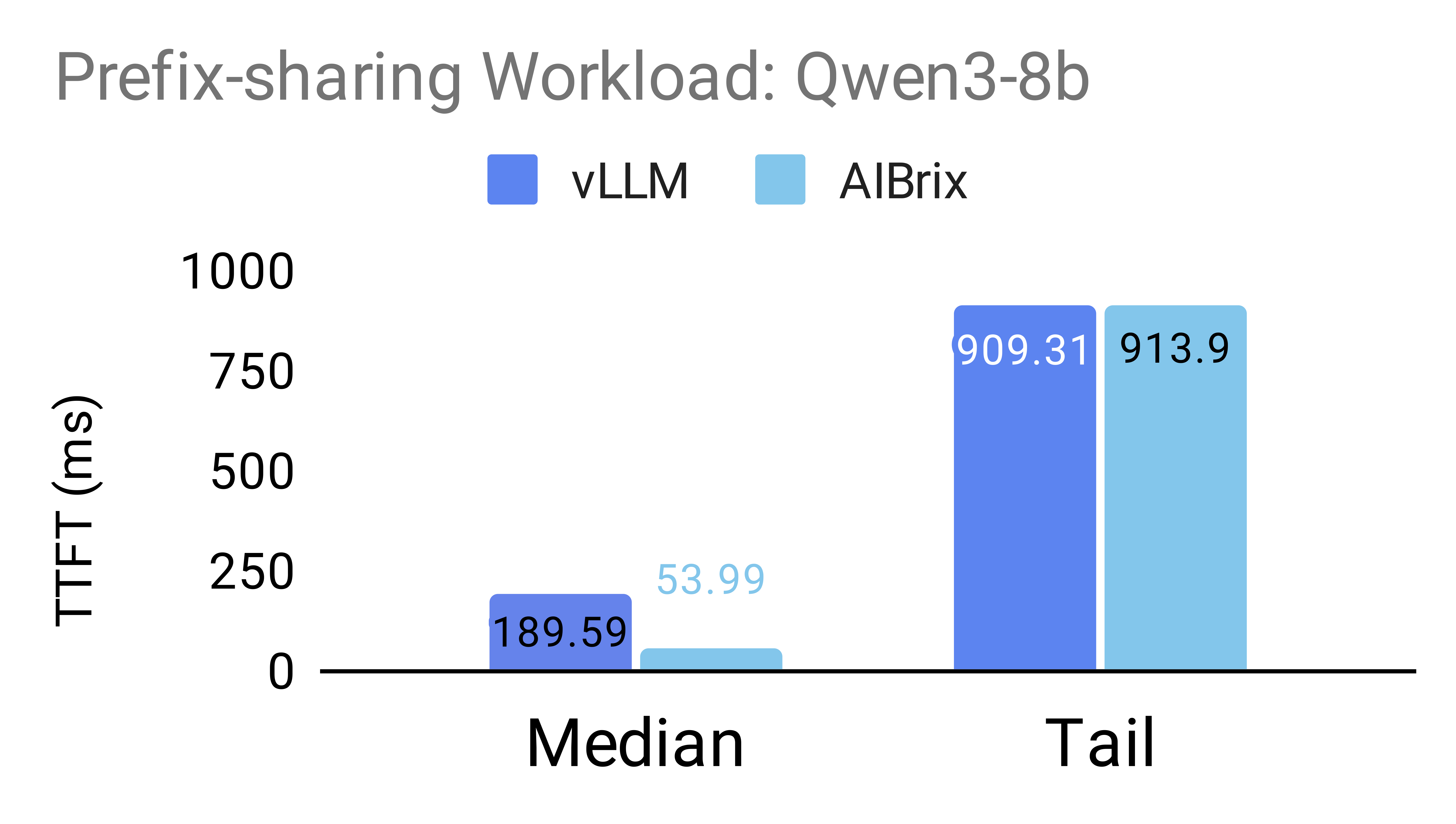
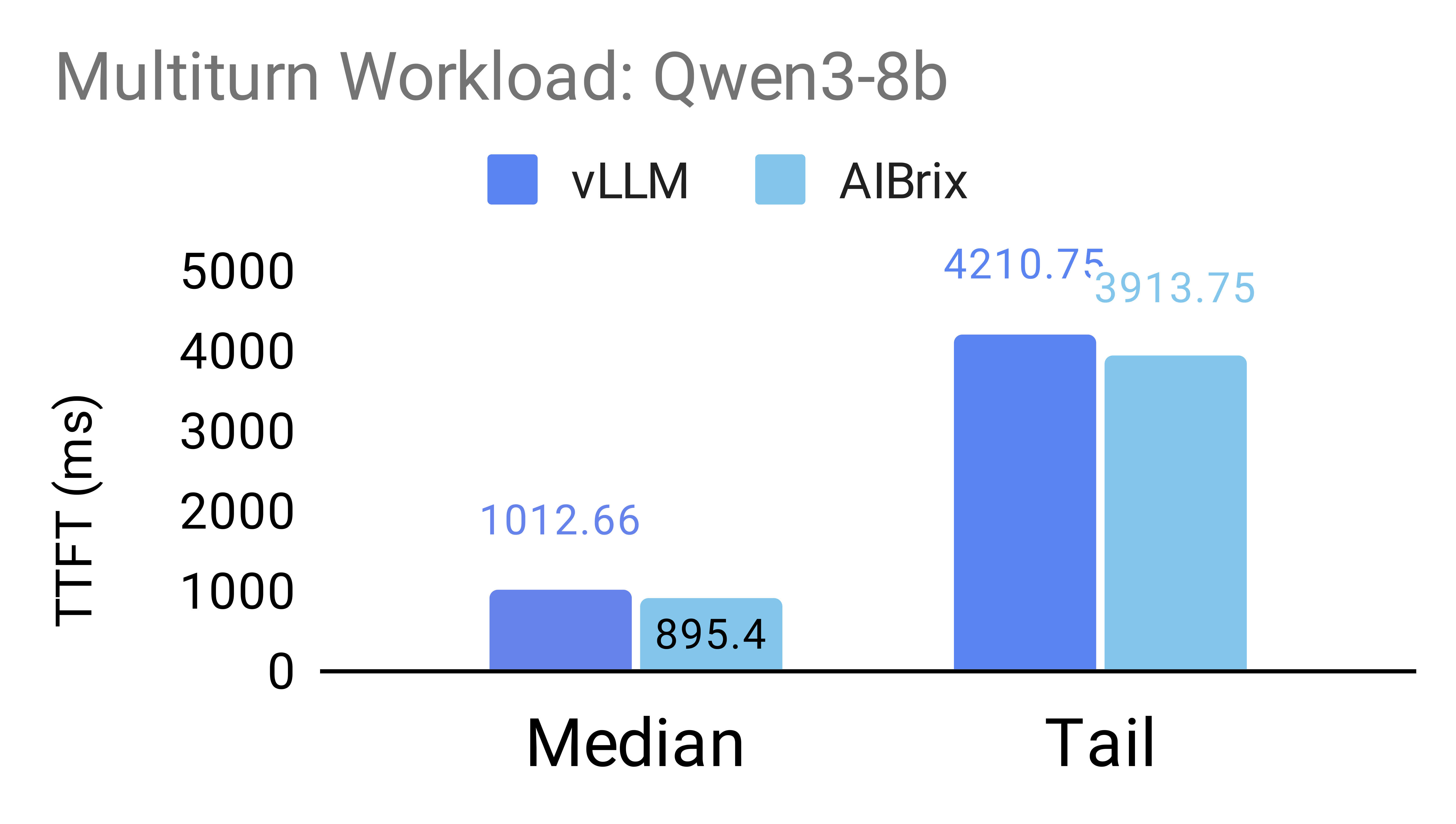
Qwen3-8b
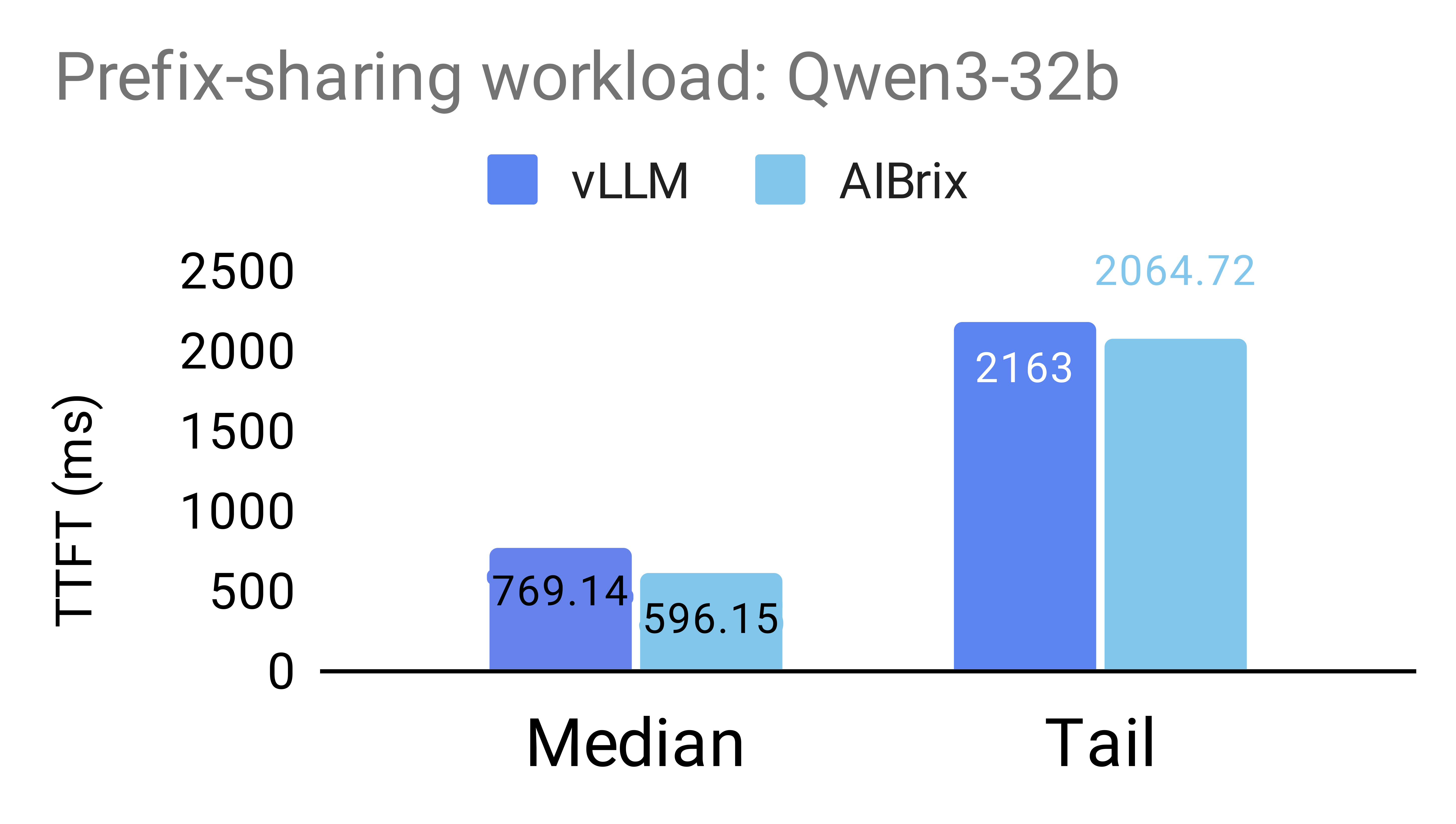
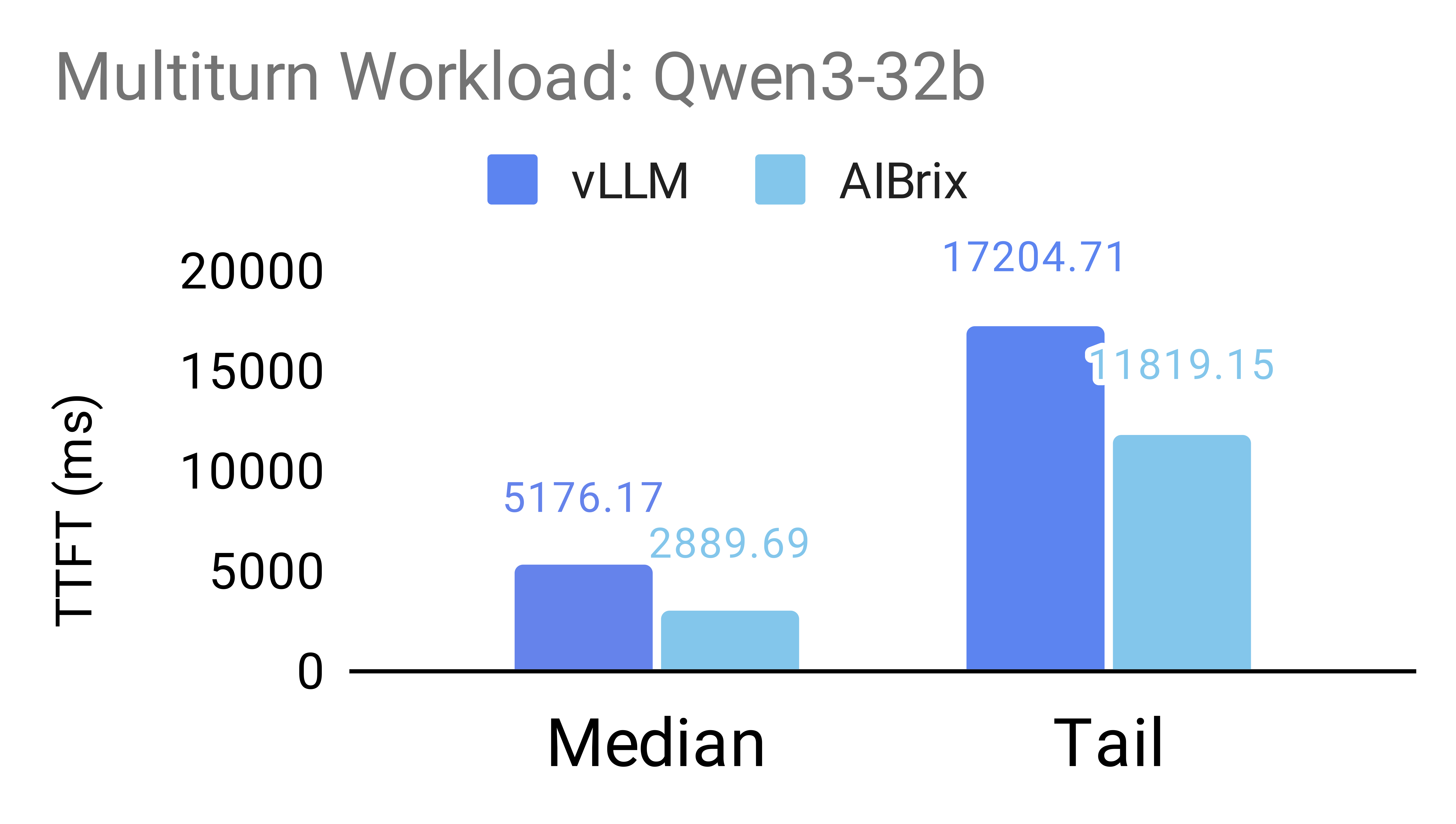
Qwen3-32b
Note: Due to the limited number of instances and high traffic saturation, the tail latency improvement is less pronounced in this setup. With more instances provisioned, the benefits of AIBrix would become more significant, especially under bursty or high-concurrency workloads.
The following figures demonstrate the substantial benefits of P/D disaggregation in reducing inference-time latency (ITL) under increasing request loads (RPS). Across both 1p1d and 2p1d configurations, P/D disaggregation consistently outperforms the non-PD baseline, maintaining lower latency in both vLLM (v0.10.0) and SGLang(v0.4.9.post3) engines. The performance gains are particularly pronounced at higher loads: we observed up to 2× improvement in 95th percentile tail ITL for the 2p1d setup and over 5× improvement in median ITL for both engines in 1p1d setup at RPS2.
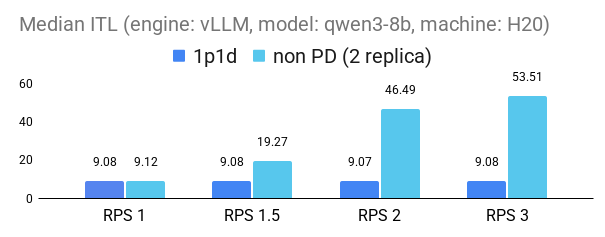
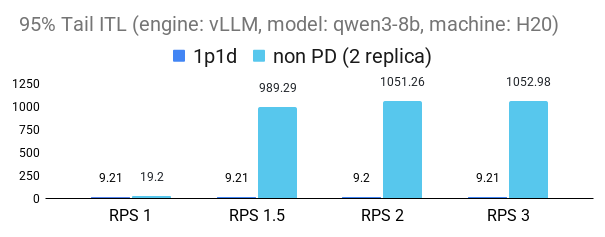
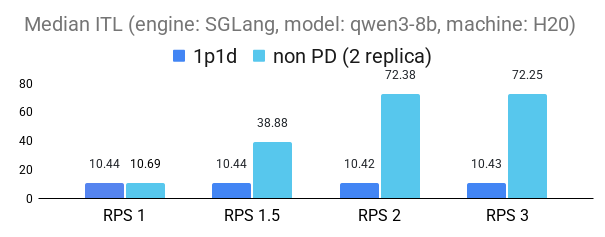
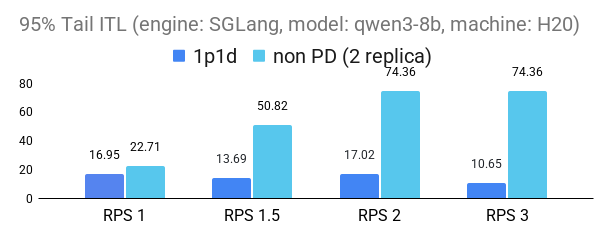
1p1d experiment setup
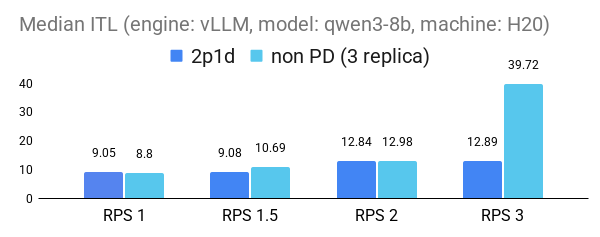

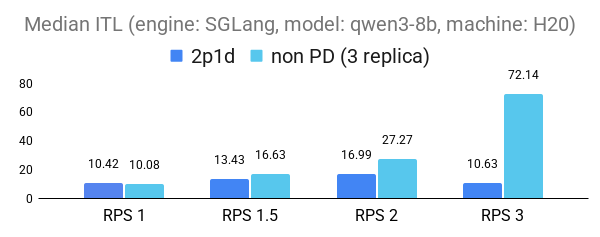

2p1d experiment setup
Large‑Scale Expert Parallelism Support
Beyond the P/D architecture, AIBrix v0.4.0 introduces enhanced support for Expert Parallelism (EP). For Mixture-of-Experts (MoE) models such as DeepSeek, EP significantly reduces the memory overhead associated with sparse FFNs. The vLLM and SGLang communities have laid a solid foundation for scalable expert parallelism by implementing EP mechanisms and integrating high-performance operator libraries like DeepEP and DeepGemm. These capabilities have been validated on cutting-edge hardware including H100 and GB200, establishing a strong technical baseline for continued innovation.
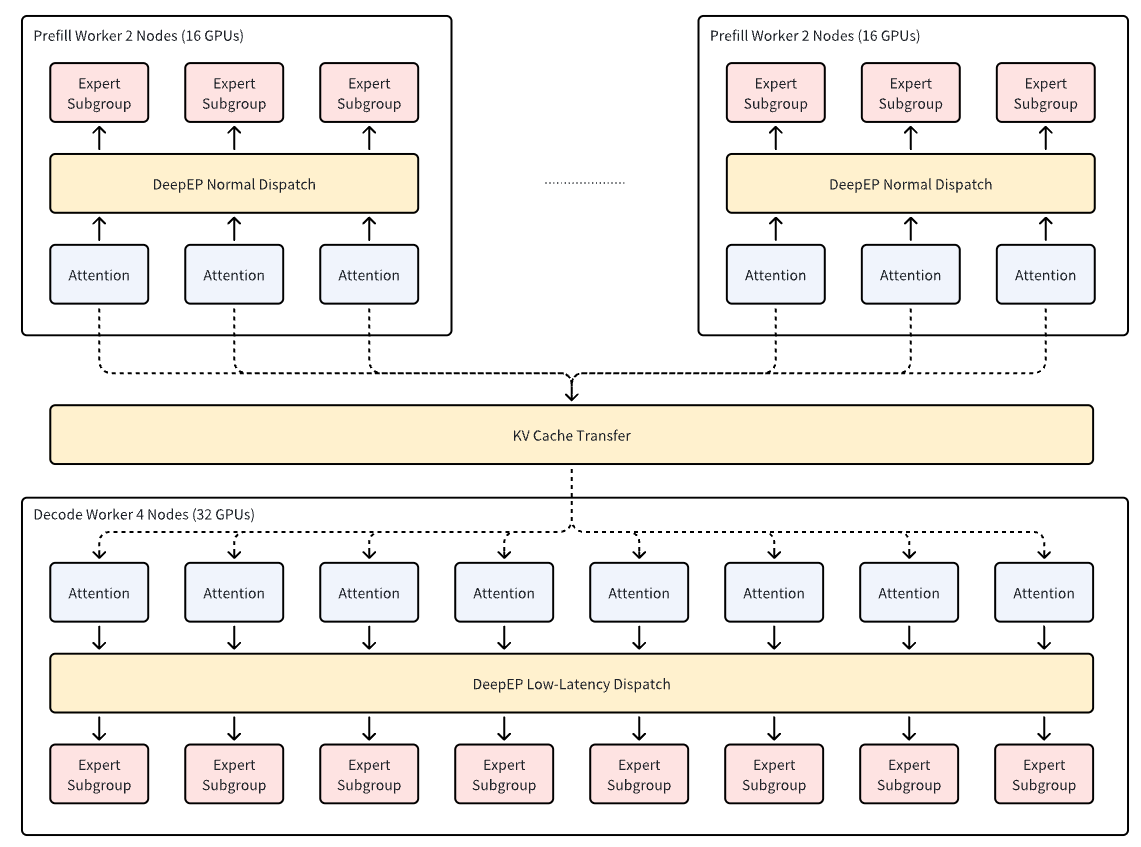
In this release, AIBrix focuses on production-grade deployment of large-scale EP. We deployed DeepSeek on 8 servers with 64 H20 GPUs, following a 2P1D configuration (two TP16 prefill workers and one TP32 decode worker). Under a 5s TTFT and 50ms TPOT constraint with 3.5k/1.5k input/output tokens, each H20 node delivered 9.0k TPS during prefill and 3.2k TPS during decode, translating to 30% increase in prefill throughput and 3.8x decoding throughput improvement over a TP16 baseline.
These results highlight AIBrix’s robust orchestration capabilities for large-scale Expert Parallelism (EP) in production environments. Beyond raw performance, AIBrix provides production-grade rollout mechanisms, including version-controlled deployment, graceful upgrades, and fault-tolerant recovery for distributed EP workloads. With AIBrix StormService, prefill and decode units can be deployed flexibly across multiple nodes, while the built-in router intelligently schedules requests to maximize GPU utilization and system throughput. Volcano Engine has officially integrated AIBrix into its Serving Kit, delivering production-grade serving for large-scale Expert Parallelism (EP) deployments. Feel free ti reach out through the Serving Kit page to explore and try it out!
KVCache v1 Connector
In our v0.3.0 release, we open-sourced the KVCache offloading framework and integrated it with vLLM v0.8.5 (V0 architecture). Now, with v0.4.0, we further optimized the framework and integrated it into vLLM v0.9.1 (V1 architecture), improving compatibility and performance.
The latest version brings several key features and enhancements:
- Achieved full support to vLLM v0.9.1’s V0 and V1 architectures.
- Enhanced observability with new profiling capabilities and flame graph visualization.
- Reduced framework overhead to under 3% (measured on a 70B model with TP=8).
- Offered network auto-configuration functionality for RDMA-capable environments.
- Introduced new AIBrix KVCache L2 connectors for PrisDB and EIC, ByteDance’s key-value stores engineered for low-latency, scalable multi-tier caching architectures optimized for LLM inference workloads.
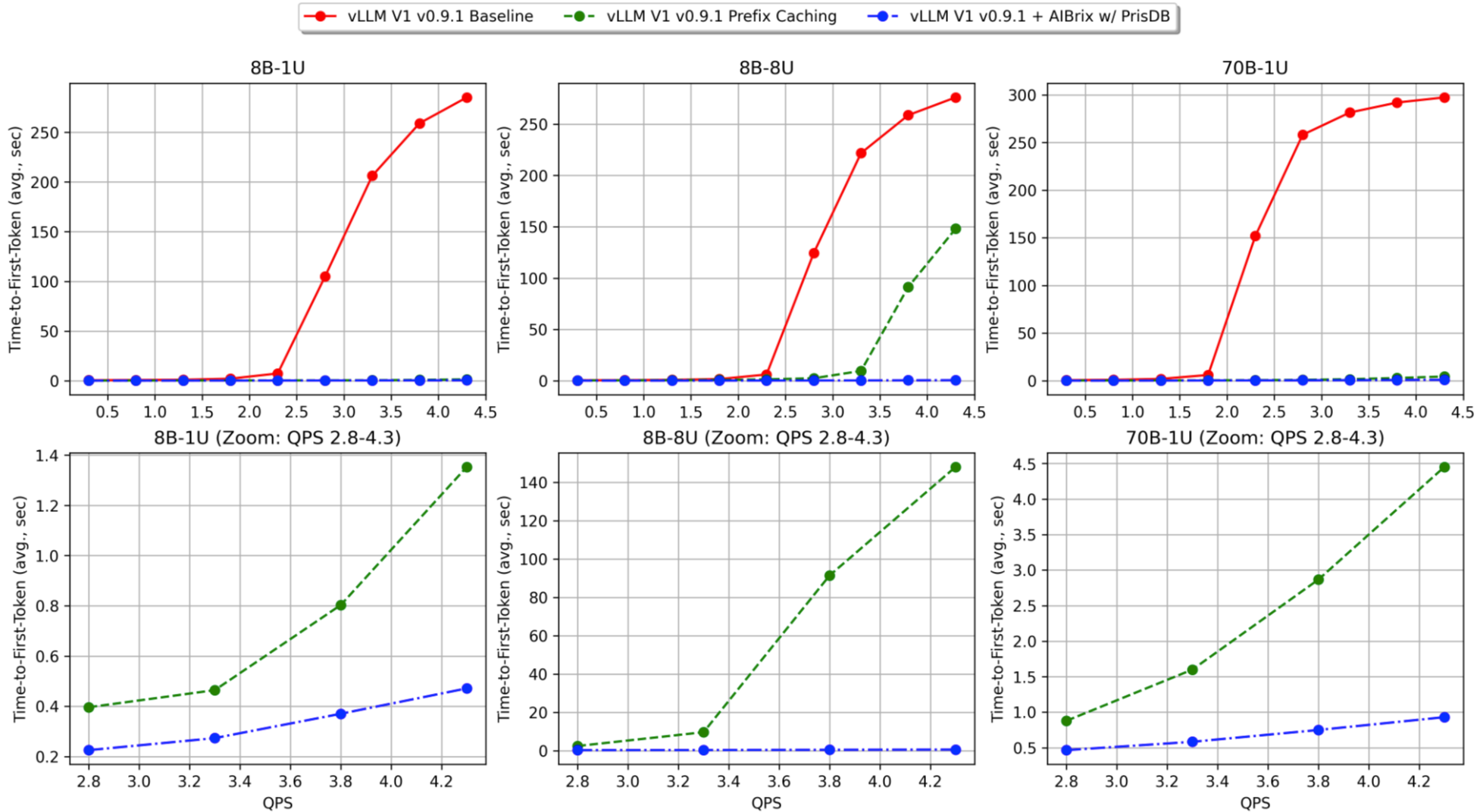
Benchmarks by the Elastic Instant Cache(EIC) team demonstrate 89.27% reduction in average TTFT and 3.97x throughput improvement under high-concurrency scenarios (70B model). We also conducted the same benchmarks as v0.3.0 using PrisDB as the L2 cache backend. These benchmarks are carried out with two simulated production workloads. Both workloads maintain identical sharing characteristics but different scaling. All unique requests in Workload-1 can be fit in the GPU KV cache, while Workload-2 scales the unique request memory footprint to 8 times, simulating capacity-constrained use cases where cache contention is severe. Compared to vLLM Baseline (w/o prefix caching) and vLLM Prefix Caching, AIBrix + PrisDB shows superior TTFT performance, particularly under increasing QPS. The following figure shows that AIBrix + PrisDB delivers sub-second TTFT and orders of magnitude TTFT advantages across all load levels and benchmarks.
(Notation: 8B-1U = DeepSeek-R1-Distill-Llama-8B + Workload-1; 8B-8U = Workload-2 variant; 70B-1U = DeepSeek-R1-Distill-Llama-70B model + Workload-1)
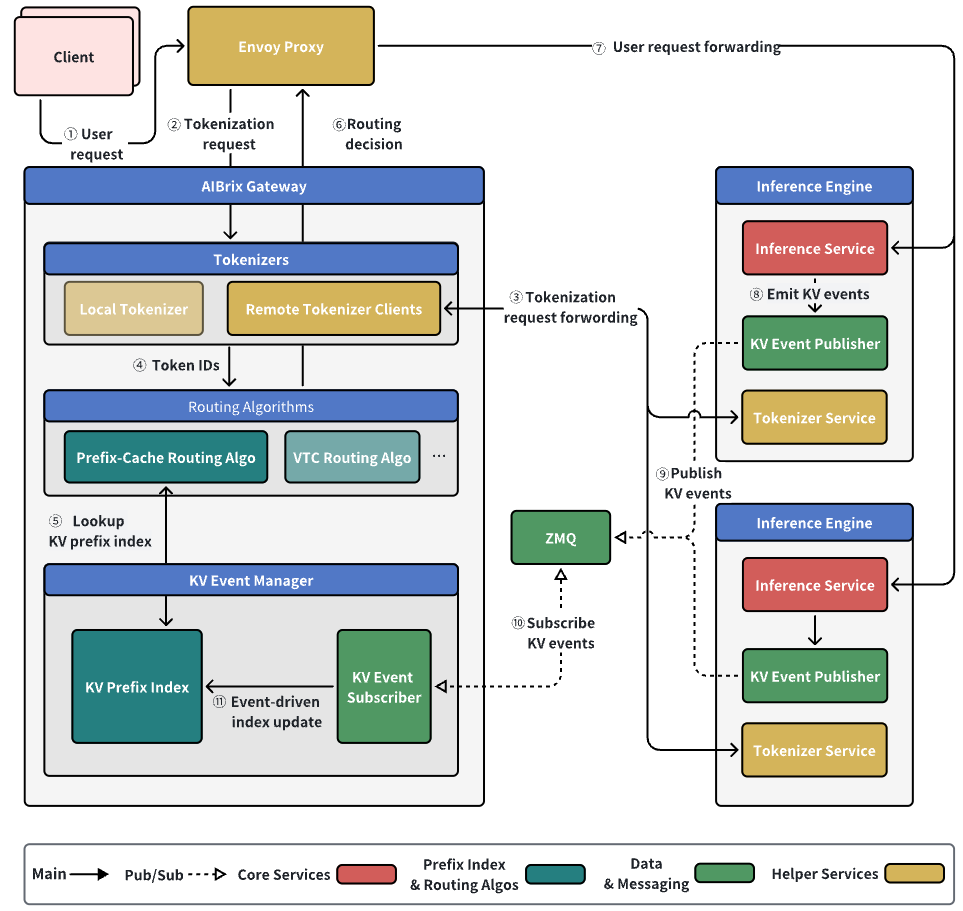
KV Event Subscription System
AIBrix v0.4.0’s new KV Event Subscription System improves prefix cache hit rates by synchronizing KV cache states in real-time across distributed nodes. The introduction of this new system offers a choice with different trade-offs, allowing users to decide between system simplicity and prefix cache state accuracy based on their needs.
The core idea of this feature is to broadcast KV cache state change events across all routers via messaging middleware. This provides the routing layer with a near real-time, global view of the cache, enabling more precise routing decisions. (See PR #1349 for details)
In theory, global state synchronization can significantly improve the cluster’s potential prefix cache hit rate. However, this advantage comes at a cost. The approach introduces additional overhead from message queue management, increasing system complexity. In the current version, performance gains are not guaranteed, as the routing algorithms have not yet been fully adapted. Furthermore, the indexer may face scalability challenges in large-scale deployments.
In contrast, the traditional unsynchronized approach is simpler and more lightweight, requiring no extra synchronization components. Its main drawback is the potential for inconsistencies, as each node runs its eviction policies independently, which can lower the overall cluster’s prefix cache hit rate.
To enable the KV event subscription system, the remote tokenizer mode must be active, and the following environment variables must be set in gateway plugin component:
// Enable KV event synchronization
AIBRIX_KV_EVENT_SYNC_ENABLED: true
// Depends on and enables remote tokenizer mode
AIBRIX_USE_REMOTE_TOKENIZE: true
If synchronization is disabled, the router automatically falls back to the original prefix cache routing logic.
The KV Event Subscription System is a step for AIBrix towards high-performance distributed prefix caching. Our future work will focus on deeply optimizing the routing algorithms and enhancing the scalability of core components like the indexer to fully realize the system’s potential.
Multi‑Engine Support
Previously, AIBrix primarily supported the vLLM engine, limiting flexibility for comparing different inference backends. However, growing community demand—as seen in #137, #843, and #1245 —highlighted the need for broader engine support. With the latest update, AIBrix now supports multi-engine deployment, allowing developers to run vLLM, SGLang, and xLLM side-by-side within a single AIBrix cluster. This unlocks new possibilities for benchmarking and production deployment while leveraging AIBrix’s unified serving infrastructure.
Key points include:
- Label configuration: add
model.aibrix.ai/engineto the pod YAML to specify the engine type and usemodel.aibrix.ai/nameand related labels to identify the model. For example, mark an vLLM deployment withengine: "vllm" - Metric mapping: AIBrix selects different metrics based on engine type—for instance, vLLM’s
avg_generation_throughput_toks_per_sversus SGLang’sgen_throughput. If the desired metric is unsupported, the router falls back to the random strategy. - Extensibility: to add a new engine, you simply map metric names in the code and declare the engine in the deployment template; AIBrix then adapts to the new metrics sources.
Multi‑engine support makes it easy to run vLLM and SGLang side‑by‑side and facilitates model migration or A/B testing. As more engines join, the community can use this mechanism to explore different inference stacks.
Other Improvements
While the highlights focus on new architectural and orchestration capabilities, we’ve also delivered several foundational improvements that strengthen AIBrix’s robustness and observability in real-world deployments.
AIBrix Gateway now supports SLO-aware routing with request profiling and deadline-based traffic control, enabling more intelligent and responsive load handling under dynamic traffic patterns (#1192, #1305, #1368). Additional enhancements include configurable timeouts, custom metrics ports, and a ready-to-use Grafana dashboard for observability (#1211, #1212).
On the control plane side, we’ve strengthened webhook validation, CRD existence checks, and added mechanisms to safely resync cache state during component restarts (#1170, #1187, #1219).
We’ve also resolved critical issues around router accuracy, prefix cache scalability, response body parsing, and autoscaler misconfigurations, making the system more stable and production-ready (#1246, #1262, #1173).
For a full list of changes, commit history, and contributor details, please check out the AIBrix v0.4.0 Release Notes.
Contributors & Community
We thank all contributors who participated in this release and the community users who provided feedback and testing. Special thanks to our first-time contributors:
@dittops, @yyzxw, @firebook, @windsonsea, @emmanuel-ferdman, @MondayCha, @learner0810, @jiahuipaung, @didier-durand, @gcalmettes, @justadogistaken, @ModiCodeCraftsman, @haitwang-cloud, @nicole-lihui, @omerap12, @li-rongzhi, @rudeigerc, @Yaegaki1Erika, @elizabetht, @Epsilon314 🙌
We also promote two maintainers @xunzhuo and @googs1025. They’ve shown consistent contributions and leadership in areas like controller management and gateway routing, and we look forward to their ongoing impact in driving AIBrix forward.
We deeply appreciate your contributions and feedback. Keep them coming!
Next Steps
We’re continuing to push the boundaries of LLM system infrastructure, and AIBrix v0.5.0 will focus on unlocking powerful capabilities for agent-based use cases, multi-modality, and cost-efficient multi-tenant serving. Here’s a glimpse of what’s coming:
- P/D Disaggregation Improvements: Introduced additional production-ready deployment patterns and examples, with improved integration of PodGroup for better scheduling alignment and enhanced autoscaling support.
- Batch API: Introduce a new batch inference API to improve GPU utilization under latency-insensitive scenarios.
- Multi-Tenancy: Add tenant-aware isolation, request segregation, and per-tenant SLO controls for safer shared deployments.
- Context Cache for Agents: Enable efficient reuse of session history across multi-turn conversations and agentic programs via a new context caching interface.
- Multi-Modal Support: Extend KVCache and runtime support to vision and embedding models, laying the groundwork for multimodal serving.
If you’re building advanced LLM systems and want to get involved—join the discussion or contribute on GitHub!