AIBrix is a composable, cloud-native AI infrastructure toolkit designed to power scalable and cost-effective large language model (LLM) inference. As production demands for memory-efficient and latency-aware LLM services continue to grow, we’re excited to announce the v0.3.0 release of AIBrix. This release brings major architectural enhancements—including KVCache offloading, smarter prefix caching, load-aware routing strategies, robust benchmarking support, and improved system stability.
This release focuses on three key challenges for LLM inference systems:
- Efficient multi-level KV caching for token reuse across engine
- Intelligent routing for fair, low-latency traffic distribution
- Reproducible performance evaluation based on real-world workload traces
We introduce a fully integrated distributed KVCache offloading system, adaptive routing logic, and a benchmarking framework. The control and data planes have been refactored for production readiness and extensibility.
New Features!
Multi-tier KV Cache Offloading System
In the AIBrix v0.2.0 release, we introduced distributed KVCache for the first time by integrating Vineyard and making experimental changes in vLLM. This early design aimed to address a key bottleneck in LLM inference: as model sizes and context lengths grow, KV cache increasingly consumes GPU memory and limits scalability. However, v0.2.0 had notable limitations — the KVConnector interface in vLLM had only just been merged upstream, and we hadn’t yet had the opportunity to fully leverage it or build a dedicated cache server optimized for LLM workloads. Meanwhile, systems like Dynamo, MoonCake, and LMCache explored KV offloading to CPU, SSDs, or remote memory—but their multi-tier designs remain incomplete or limited: Dynamo lacks a full implementation, other solutions employ weak eviction strategies, allocation efficiencies can not meet the needs etc.
With AIBrix v0.3.0, we close these gaps and introduce a production-ready KVCache Offloading Framework, which enables efficient memory tiering and low-overhead cross-engine reuse. By default, the framework leverages L1 DRAM-based caching, which already provides significant performance improvements by offloading GPU memory pressure with minimal latency impact. For scenarios requiring multi-node sharing or larger-scale reuse, AIBrix allows users to optionally enable L2 remote caching, unlocking the benefits of a distributed KV cache layer. This release also marks the debut of InfiniStore(https://github.com/bytedance/infinistore), a high-performance RDMA-based KV cache server developed by Bytedance, purpose-built to support large-scale, low-latency, multi-tiered KV caching for LLM inference workloads.
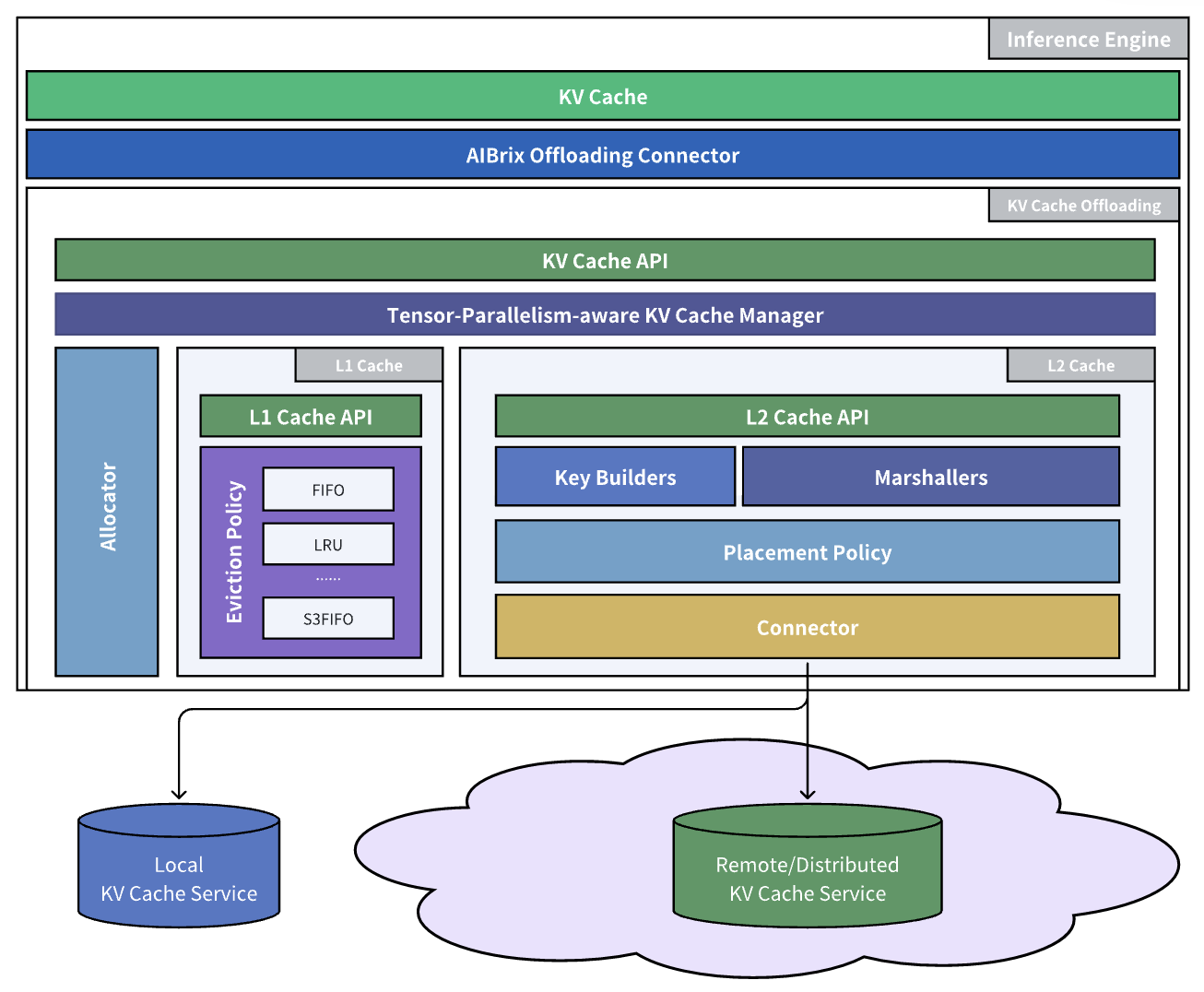
At the data plane, AIBrix integrates directly with vLLM through AIBrix Offloading Connector—a high-performance bridge designed to move data efficiently between GPU and CPU. This connector leverages optimized CUDA kernels to accelerate KV tensor transfers, minimizing overhead on critical inference paths. To scale beyond GPU memory limits, the offloading framework features a multi-tiered cache manager that dynamically distributes KV data across storage layers, including DRAM and RDMA-interconnected backends. This ensures large sessions and long prompts can be served without sacrificing batch size or latency. AIBrix KVCache Connector supports pluggable eviction strategies (e.g., LRU, S3FIFO) and flexible backends (e.g., InfiniStore) to adapt to different workload patterns and hardware environments.
Additionally, we’ve refactored the existing KVCache CRD to support new backends such as InfiniStore, enabling broader compatibility and deployment flexibility. AIBrix now leverages multiple cache servers organized via a consistent hashing ring, allowing inference engines to seamlessly communicate with distributed KV nodes. This, combined with a built-in cache placement module and coordination with the global cluster manager, enables cross-engine KV reuse—transforming previously isolated caches into a unified, shared KV infrastructure.

This architecture not only improves token reuse and system throughput but also reduces GPU memory pressure, making it easier to deploy large models reliably at scale. Here are some benchmarks we have done. Our benchmarks cover two scenarios:
- Scenario-1 simulates the workload pattern of one of our internal production systems;
- Scenario-2 simulates the workload pattern of a multi-turn conversation application.
For Scenario-1, we construct two workloads (i.e., Workload-1 and Workload-2) from the same workload profile derived from real-world usage patterns observed in our internal production systems. Both workloads maintain identical sharing characteristics but different scaling. All unique requests in Workload-1 can be fit in the GPU KV cache, while Workload-2 scales the unique request memory footprint to 8 times, simulating capacity-constrained use cases where cache contention is severe. Note that configurations for workload generation and steps to reproduce these benchmarks will be released shortly in AIBrix repository.
Figure 1 and Table 1 illustrate the performance results of all systems (Cache-X is another KVCache offloading system in the community) with Workload-1. Compared to other systems, AIBrix shows superior TTFT performance, particularly under increasing QPS. Both AIBrix L1 and AIBrix + InfiniStore deliver sub-second P99 TTFT across all load levels. For Workload-2, as shown in Figure 2 and Table 2, AIBrix + InfiniStore continues to demonstrate orders of magnitude TTFT advantages across all load conditions because of InfiniStore’s low-latency access and massive capacity.
Figure 1: Average Time to First Token (seconds) with Varied QPS - Workload-1
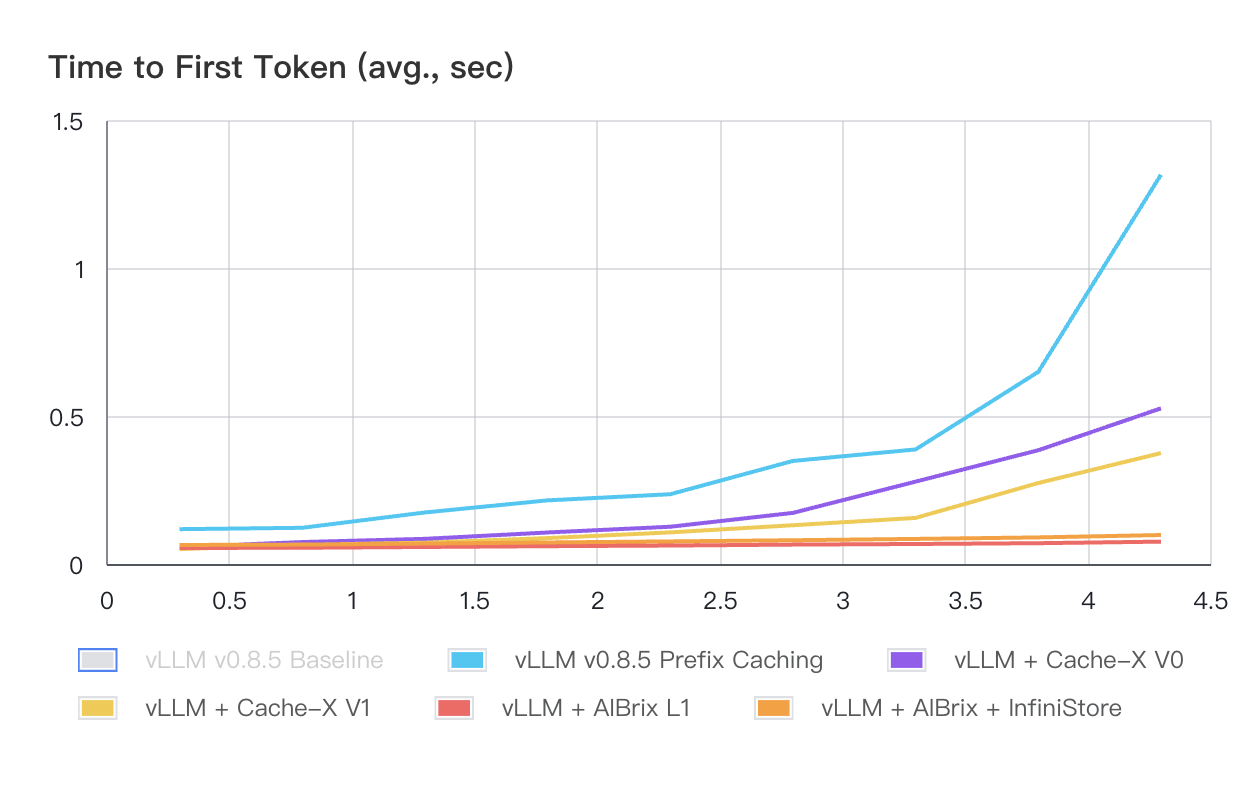
Note: The vLLM baseline is EXCLUDED from this chart because its performance is significantly worse than others’, making their curves difficult to distinguish at this scale.
Table 1: Click to expand TTFT Table for Workload-1
| vLLM v0.8.5 Baseline | vLLM v0.8.5 Prefix Caching | vLLM + Cache-X V0 | vLLM + Cache-X V1 | vLLM + AIBrix L1 | vLLM + AIBrix + InfiniStore | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| QPS | Avg. | P99 | Avg. | P99 | Avg. | P99 | Avg. | P99 | Avg. | P99 | Avg. | P99 |
| 0.3 | 0.39 | 0.76 | 0.12 | 1.08 | 0.06 | 0.36 | 0.05 | 0.27 | 0.05 | 0.09 | 0.06 | 0.11 |
| 0.8 | 0.46 | 1.27 | 0.12 | 0.67 | 0.07 | 0.66 | 0.07 | 0.65 | 0.05 | 0.12 | 0.07 | 0.13 |
| 1.3 | 0.58 | 2.05 | 0.17 | 1.77 | 0.09 | 0.92 | 0.07 | 0.82 | 0.06 | 0.12 | 0.07 | 0.14 |
| 1.8 | 0.88 | 4.22 | 0.22 | 3.47 | 0.11 | 1.43 | 0.09 | 1.14 | 0.06 | 0.13 | 0.07 | 0.17 |
| 2.3 | 1.72 | 8.49 | 0.24 | 2.65 | 0.13 | 1.85 | 0.11 | 1.69 | 0.06 | 0.14 | 0.08 | 0.18 |
| 2.8 | 103.29 | 167.26 | 0.35 | 4.93 | 0.17 | 2.55 | 0.13 | 2.02 | 0.07 | 0.15 | 0.08 | 0.21 |
| 3.3 | 127.95 | 220.00 | 0.39 | 4.99 | 0.28 | 4.70 | 0.16 | 2.44 | 0.07 | 0.15 | 0.08 | 0.41 |
| 3.8 | 141.63 | 246.22 | 0.65 | 7.63 | 0.38 | 12.79 | 0.27 | 4.35 | 0.07 | 0.17 | 0.09 | 0.47 |
| 4.3 | 216.44 | 384.60 | 1.32 | 17.95 | 0.53 | 17.08 | 0.37 | 11.44 | 0.08 | 0.22 | 0.10 | 0.81 |
Figure 2: Average Time to First Token (seconds) with Varied QPS - Workload-2
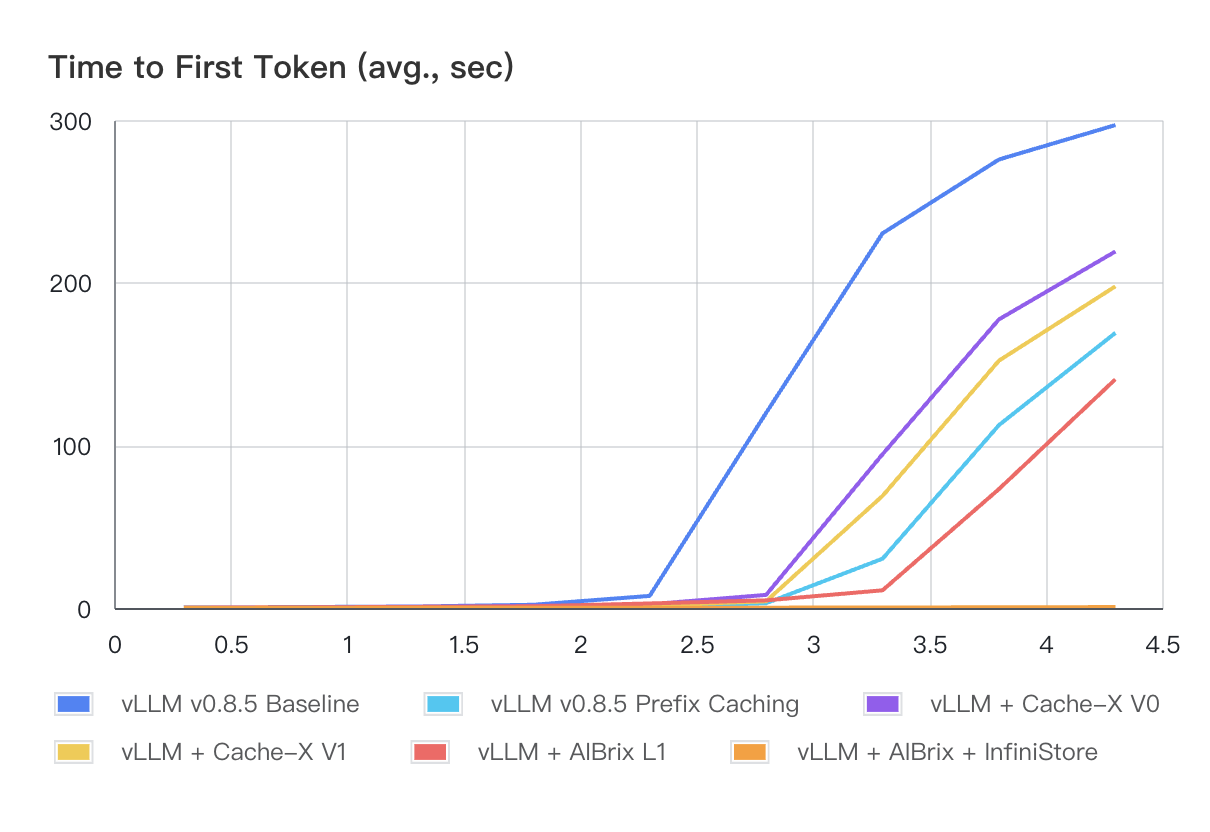
Table 2: Click to expand TTFT Table for Workload-2
| vLLM v0.8.5 Baseline | vLLM v0.8.5 Prefix Caching | vLLM + Cache-X V0 | vLLM + Cache-X V1 | vLLM + AIBrix L1 | vLLM + AIBrix + InfiniStore | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| QPS | Avg. | P99 | Avg. | P99 | Avg. | P99 | Avg. | P99 | Avg. | P99 | Avg. | P99 |
| 0.3 | 0.41 | 1.01 | 0.21 | 0.59 | 0.35 | 1.06 | 0.32 | 0.85 | 0.33 | 1.04 | 0.09 | 0.61 |
| 0.8 | 0.59 | 4.75 | 0.28 | 1.21 | 0.50 | 3.22 | 0.39 | 1.50 | 0.42 | 1.77 | 0.08 | 0.47 |
| 1.3 | 0.94 | 19.02 | 0.43 | 8.00 | 0.83 | 16.02 | 0.58 | 8.73 | 0.67 | 14.92 | 0.09 | 1.89 |
| 1.8 | 1.98 | 28.02 | 0.78 | 16.08 | 1.34 | 21.79 | 0.87 | 14.44 | 1.05 | 19.11 | 0.12 | 2.65 |
| 2.3 | 7.44 | 43.67 | 1.36 | 23.28 | 2.28 | 30.33 | 1.53 | 22.75 | 2.80 | 37.70 | 0.17 | 3.70 |
| 2.8 | 119.90 | 235.08 | 2.94 | 32.64 | 8.06 | 43.87 | 4.11 | 30.02 | 4.70 | 45.29 | 0.21 | 4.13 |
| 3.3 | 230.34 | 406.14 | 30.29 | 53.43 | 94.53 | 183.23 | 68.92 | 135.68 | 10.87 | 44.85 | 0.33 | 5.02 |
| 3.8 | 275.73 | 429.01 | 112.45 | 210.21 | 177.45 | 332.48 | 152.06 | 295.40 | 73.13 | 116.05 | 0.42 | 9.85 |
| 4.3 | 296.89 | 429.40 | 169.14 | 279.82 | 219.18 | 361.50 | 197.74 | 304.80 | 140.62 | 238.98 | 0.58 | 16.20 |
For Scenario-2, we construct a workload (i.e., Workload-3) that theoretically consumes 8 times of GPU KV cache capacity to showcase the advantages of KV cache offloading for multi-turn conversation applications. As shown in Table 3, the performance comparison highlights several key insights. 1) Cache-X V1 outperforms V0 due to its ability to overlap I/O and computation, reducing idle time (“bubble”) in the execution pipeline. 2) When comparing AIBrix solutions with Cache-X, AIBrix L1 delivers performance on par with Cache-X V0, while AIBrix + InfiniStore, because of its larger capacity, achieves the lowest latencies across all QPS levels. AIBrix KVCache will support vLLM V1’s KV connector as well to further squeeze the bubble between I/O and computation in order to deliver more optimized effectiveness and efficiency.
Figure 3: Average Time to First Token (seconds) with Varied QPS - Workload-3
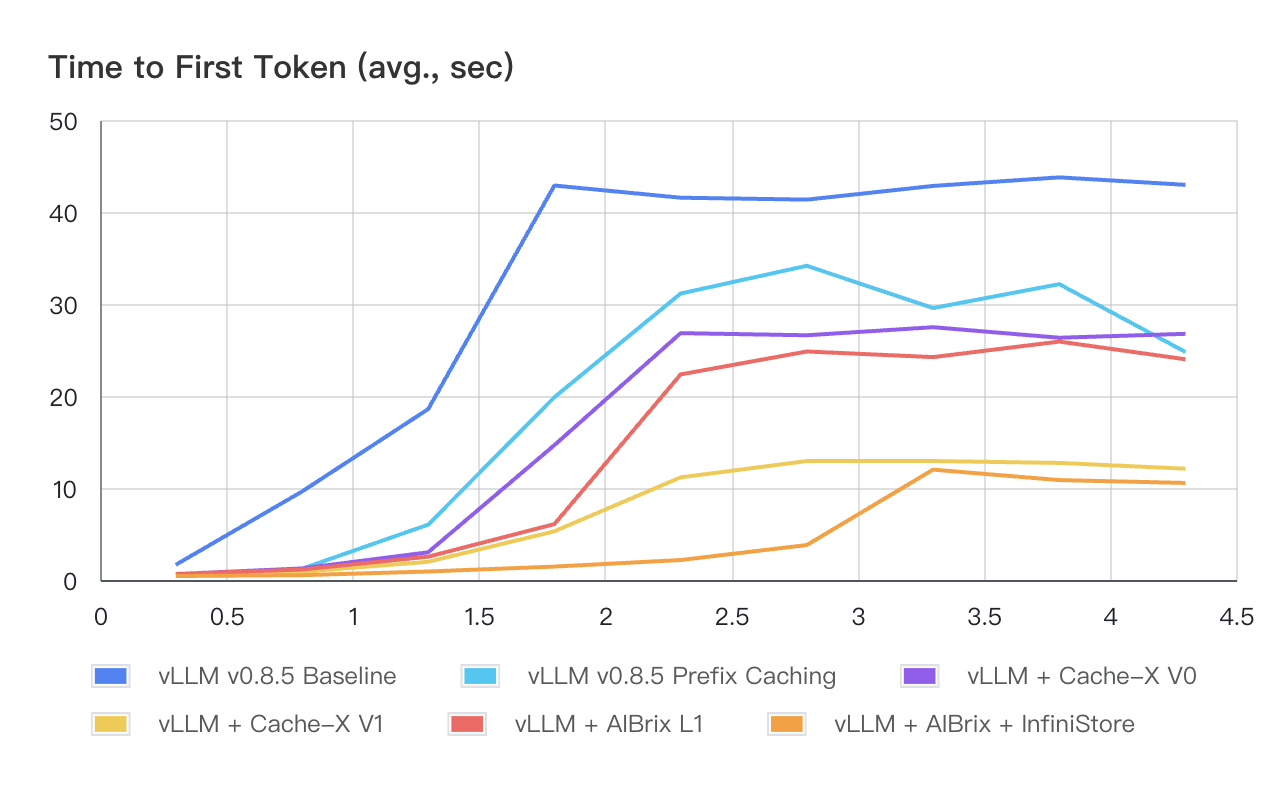
Table 3: Click to expand TTFT Table for Workload-3
| vLLM v0.8.5 Baseline | vLLM v0.8.5 Prefix Caching | vLLM + Cache-X V0 | vLLM + Cache-X V1 | vLLM + AIBrix L1 | vLLM + AIBrix + InfiniStore | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| QPS | Avg. | P99 | Avg. | P99 | Avg. | P99 | Avg. | P99 | Avg. | P99 | Avg. | P99 |
| 0.3 | 1.65 | 8.90 | 0.45 | 2.92 | 0.65 | 3.24 | 0.58 | 2.24 | 0.66 | 2.72 | 0.43 | 1.93 |
| 0.8 | 9.61 | 59.26 | 1.22 | 9.08 | 1.25 | 9.25 | 0.90 | 7.14 | 1.14 | 6.48 | 0.52 | 2.15 |
| 1.3 | 18.58 | 59.29 | 6.01 | 41.29 | 3.01 | 17.55 | 1.98 | 13.00 | 2.53 | 12.39 | 0.93 | 5.44 |
| 1.8 | 42.88 | 106.85 | 19.87 | 81.10 | 14.66 | 40.06 | 5.29 | 20.67 | 6.07 | 19.70 | 1.46 | 8.66 |
| 2.3 | 41.55 | 109.56 | 31.14 | 82.19 | 26.83 | 54.34 | 11.16 | 32.42 | 22.35 | 51.36 | 2.17 | 11.38 |
| 2.8 | 41.34 | 98.44 | 34.15 | 87.31 | 26.60 | 57.26 | 12.93 | 34.14 | 24.84 | 50.89 | 3.80 | 16.15 |
| 3.3 | 42.83 | 96.59 | 29.56 | 84.44 | 27.48 | 56.35 | 12.93 | 34.46 | 24.23 | 49.62 | 11.99 | 36.44 |
| 3.8 | 43.77 | 109.12 | 32.16 | 90.08 | 26.33 | 57.08 | 12.72 | 33.85 | 25.91 | 51.20 | 10.86 | 29.18 |
| 4.3 | 42.95 | 93.38 | 24.78 | 77.92 | 26.76 | 55.20 | 12.10 | 33.06 | 23.99 | 51.99 | 10.55 | 26.62 |
Enhanced Routing Capabilities
This release upgrades routing logic with intelligent, adaptive strategies for LLM serving:
- Prefix-aware Routing: Uses hash token-based prefix matching and load awareness for reduced latency.
- Preble: An implementation of ICLR'25 Preble, it balances KV cache reuse and GPU load using prefix length and a prompt-aware cost mode.
- Fairness-oriented Routing: An implementation of OSDI’24 VTC, it introduces the
vtc-basicrouter with Windowed Adaptive Fairness Routing algorithm that enforces load fairness through dynamic token tracking and adaptive pod assignment.
2.1 Prefix-Cache Routing
Inference engine such as vLLM provides prefix-caching where KV cache of existing queries is cached such that a new query can directly reuse the KV cache if it shares the same prefix with one of the existing queries, allowing the new query to skip the computation of the shared part. To take advantage of this feature, AIBrix gateway introduces prefix-cache aware routing to achieve this goal. Some high level design details are
Prefix-cache routing, does load balancing to ensure no hot spots are created i.e. all requests sharing the same prefix are intelligently balanced across pods. Goal here to increase prefix-cache sharing without creating a hot-spot (more implementation details, PR). Observed ~45% improvement in TTFT (averaged across different request patterns) with prefix-cache compared to random routing.
Prefix-cache supports multi-turn conversation, gateway’s router identifies multi-turn conversation and routes such requests efficiently to ensure KV cache sharing.
To use prefix-cache routing, include header
"routing-strategy": "prefix-cache".
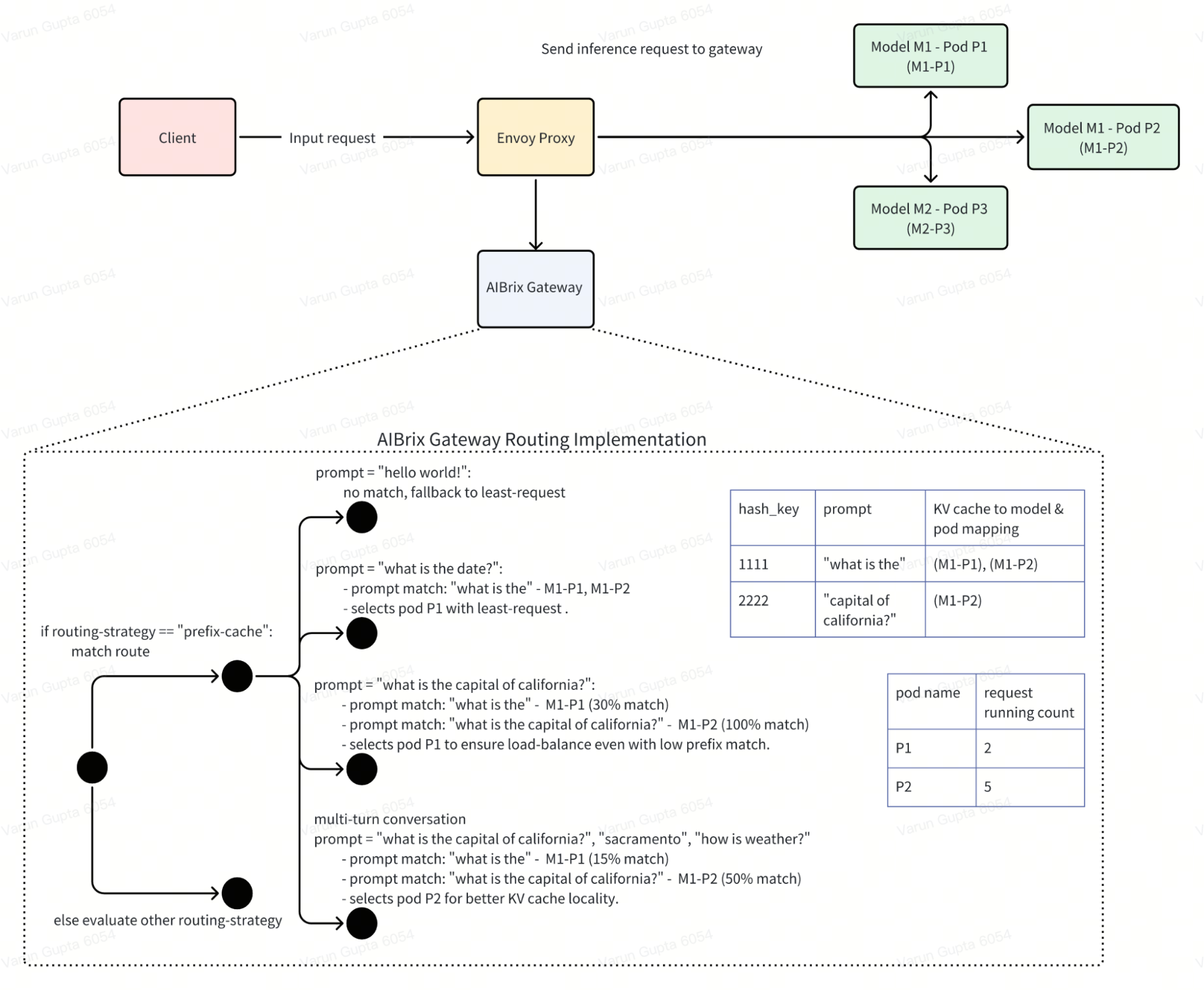
2.2 Preble Paper based: Prefix-Cache Routing Implementation
Preble is a prefix-cache routing strategy designed to efficiently handle long prompts with partially shared prefixes across requests. It co-optimizes KV cache reuse and computation load-balancing. The key insight is that when prompts share prefixes, caching and reusing computed KV states across requests dramatically improves performance. However, this reuse must be balanced with system load.. Preble operates as follows: if the shared prefix is longer than the unique suffix of a prompt, the request is routed to a GPU that already has the longest matching prefix cached. Otherwise, it routes the request to another GPU to balance the load.
Load Balancing: when the shared prefix portion is smaller than a configurable threshold (e.g., 50%), it calculates a “prompt-aware load cost” for each GPU that combines three distinct cost categories, all measured in GPU computation time.
- The first component, historical computation load, captures each GPU’s recent processing activity within a time window to understand baseline utilization without needing real-time measurements.
- The second component, eviction cost, evaluates the penalty of removing cached KV states when memory is needed, weighting each potential eviction by its hit rate to preserve frequently-used prefixes.
- The final component simply estimates the new request’s processing cost on each GPU, focusing on prefill time for non-cached tokens.
By combining these three costs (L + M + P), Preble assigns each request to the GPU with the lowest total cost, effectively balancing immediate processing efficiency against long-term cluster performance. Our implementation of Preble at AIBrix was done based on the original Preble code.
To use preble based prefix-cache solution, include header
"routing-strategy": "prefix-cache-preble". Current status is experimental.
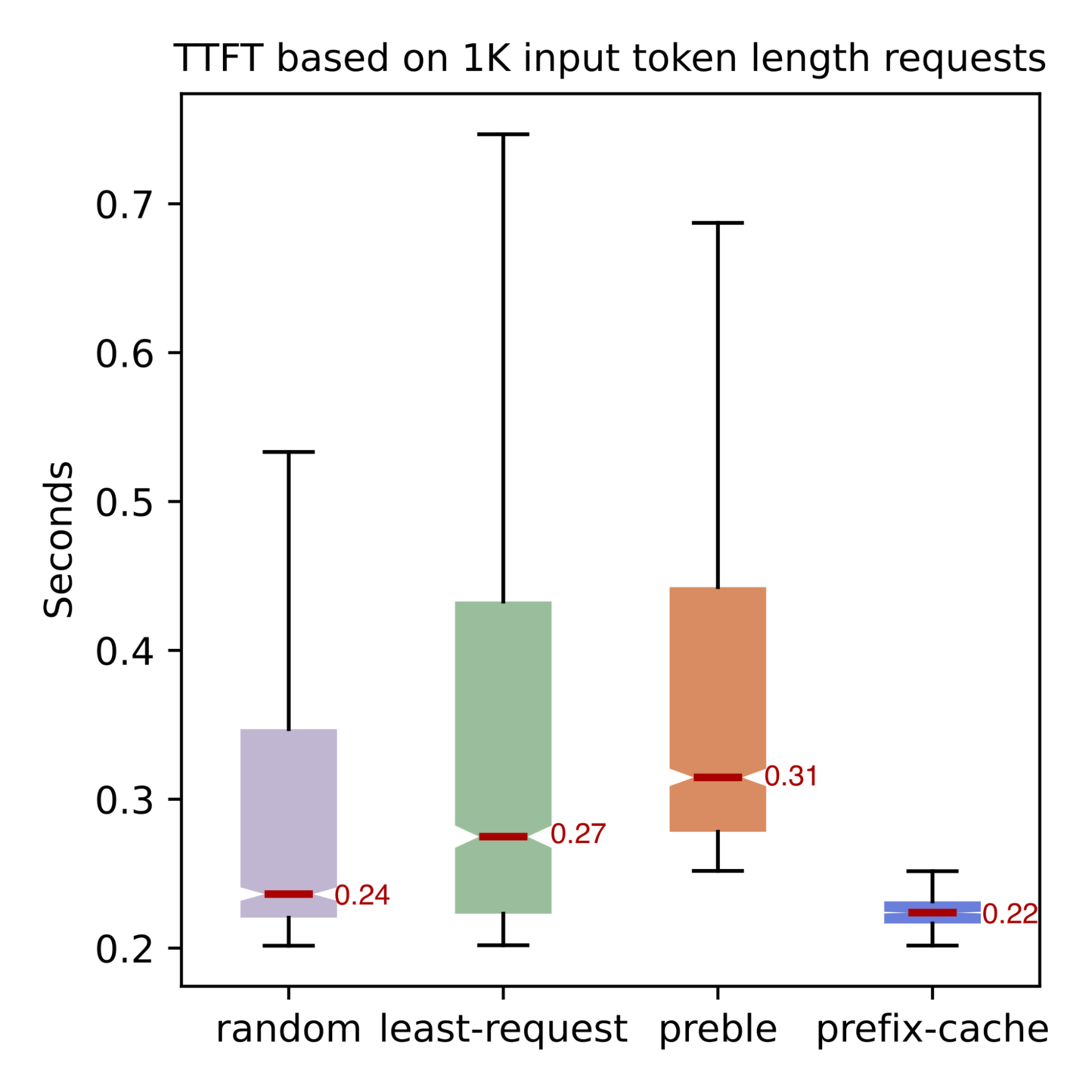
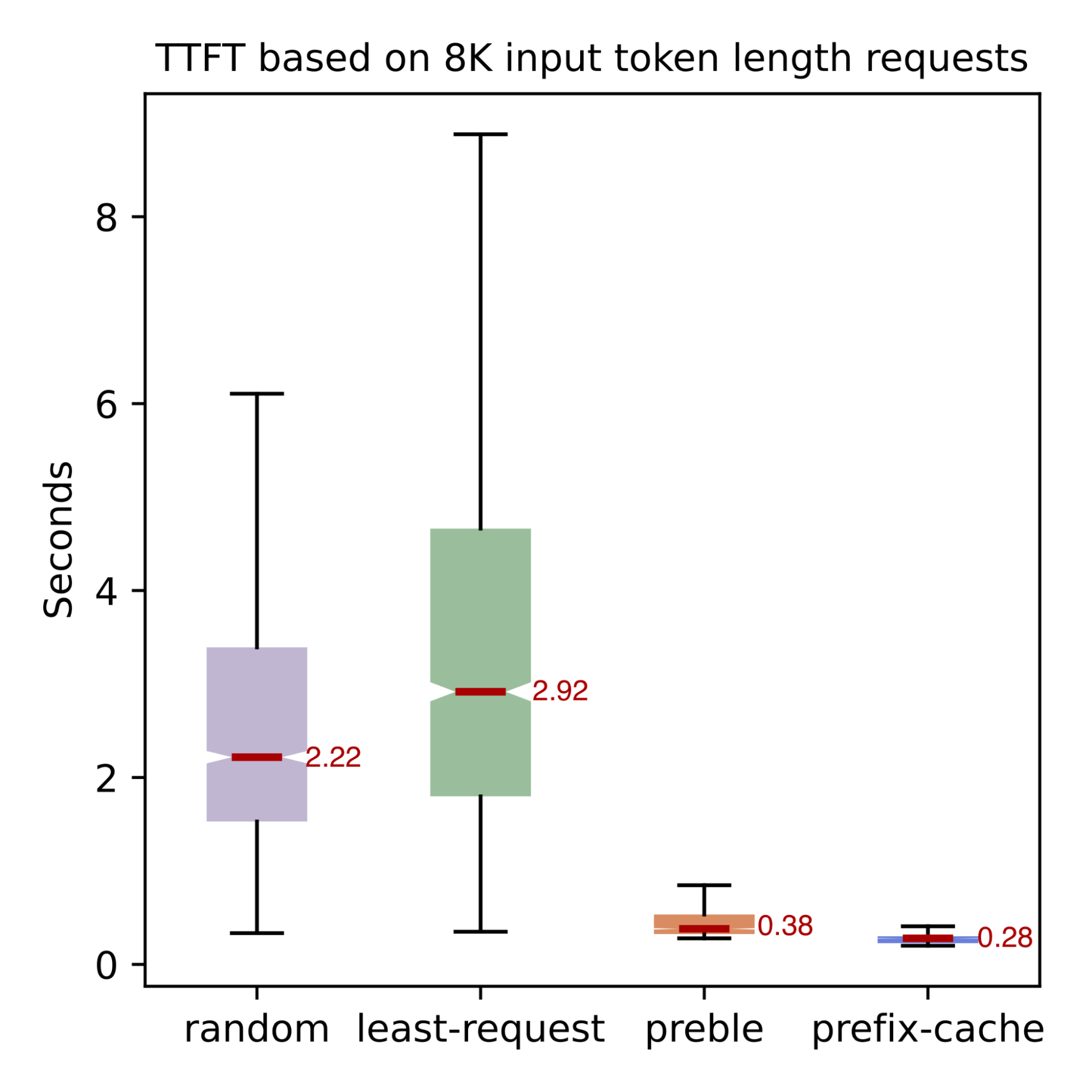
Benchmark result for different prefix cache and load aware routing strategies
2.3 Fairness-oriented Routing
The Virtual Token Counter (VTC) is a fair scheduling algorithm for LLM serving based on the paper “Fairness in Serving Large Language Models” (Sheng et al.). It aims to provide fairness among clients by tracking the service (weighted token count) each client has received and prioritizing those who have received less service. While the original paper’s implementation is designed for and evaluated in batched inference environments, we introduce a simplified version of VTC called vtc-basic in this release, for non-batched requests more suitable for the distributed and cloud native nature of AIBrix environments.
vtc-basic router implements the Windowed Adaptive Fairness Routing algorithm, which uses a windowed adaptive clamped linear approach to ensure load fairness among users. It has four key components: (1) a sliding window that tracks token usage over configurable time periods, (2) adaptive bucket sizing that dynamically adjusts based on observed token patterns, (3) clamped token values to prevent extreme sensitivity and jitter, and (4) linear mapping between tokens and pod assignments. Using these components, the router creates a hybrid scoring system that balances fairness (based on normalized user token counts) with utilization (based on current pod load) to select the pod with the lowest combined score, ensuring both fair resource allocation and efficient system utilization. Environment variables to override and configure default values of the router are available here.
To use a fairness-oriented routing, include header
"routing-strategy": "vtc-basic". Current status is experimental.
Synthetic Benchmarking & Load Generation Framework
Modern LLM deployments face unpredictable workloads, fluctuating user sessions, and a wide range of prompt/generation patterns. To meet these demands, AIBrix v0.3.0 introduces a fully modular, production-grade benchmark toolkit designed to evaluate AI inference systems with unmatched realism and flexibility.
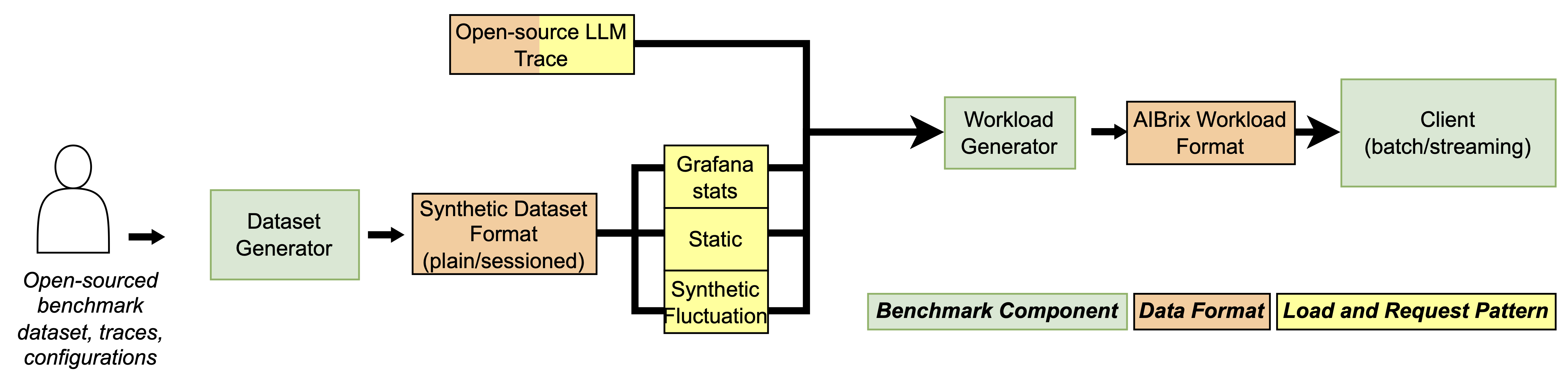
At its core, the AIBrix benchmark framework is built around a cleanly decoupled architecture: dataset generation, workload shaping, and benchmark execution. Each component can be customized independently, making it easy to plug in your own prompt logs, traffic traces, or experimental workloads—whether you’re working on a new model deployment, scaling policy, or runtime optimization.
Flexible Dataset Generation: AIBrix supports a variety of dataset formats—from flat prompt lists to multi-turn, sessioned conversations. Whether you’re generating synthetic data for stress testing or converting real client logs, the toolkit provides four flexible modes:
- Controlled Synthetic Sharing for studying prefix reuse.
- Multi-turn Synthetic Conversations for dialogue-style workloads.
- Open Dataset Conversion (e.g., ShareGPT).
- Client Log Replay with full input-output control for specific models.
Each dataset type is designed to plug seamlessly into the workload generator, enabling you to quickly iterate on prompt structures or session behavior.
Simulate Real Workloads: Unlike many synthetic or fixed-pattern tools, AIBrix is built with real-world inference behavior in mind. You can:
- Try Load Modeling by controlling runtime characteristics such as Queries per second (QPS), Prompt and generation token lengths, Session concurrency, and Time-based traffic distribution (e.g., bursty loads).
- Replay real traces from production environments (e.g., Azure LLM traces, Grafana-exported metrics).
- Model dynamic traffic fluctuations with statistical patterns.
- Evaluate session-based prompt reuse, including scenarios with controlled lengths of shared prefixes.
From steady-state baselines to high-burst or multi-session simulations, AIBrix lets you reproduce the messy realities of production traffic.
Execute, Measure, and Tune: The benchmark client supports both streaming and non-streaming APIs, collecting fine-grained latency metrics like Time-to-First-Token (TTFT) and Time-per-Output-Token (TPOT). Whether you’re studying routing behavior, KV cache backends, autoscaling metrics, AIBrix gives you the instrumentation and flexibility needed to generate insights that translate directly into production improvements.
Feature Enhancements
Beyond the core features of KV cache offloading, intelligent routing, and benchmarking, AIBrix v0.3.0 includes several production-grade improvements to enhance stability, extensibility, and operational visibility across the stack.
Gateway Enhancements
- Support for OpenAI-compatible APIs, including streaming responses, usage reporting, asynchronous handling, and standardized error responses for seamless end-to-end integration. (#703, #788, #799)
- Introduced the
/v1/modelsendpoint for compatibility with OpenAI-style API clients. (#802) - Refactored gateway-plugins with an extensible
ext-procserver architecture, laying the foundation for pluggable policies. (#810) - Improved concurrency safety and routing stability through major cache and router redesigns (#878, #884)
Control Plane
- Added Kubernetes webhook validation for CRDs, providing early error feedback during resource creation (#748, #786).
- Improve RayClusterFleet to fully support Deepseek-r1/v3 models (#789, #826, #835, #914, #954).
- Add scale subresource in RayClusterFleet CRD and enable HPA support (#1082, #1109)
Installation Experiences
- Introduced Terraform modules for GCP and Kubernetes deployment. (#823)
- Added setup guides for Minikube on Lambda Cloud and AWS in the documentation. (#1020)
- Enabled standalone controller installation for simplified system bootstrapping. (#930. #931)
- Streamlined upgrade workflows by introducing
kubectl applysupport. CRDs are now split and applied with--server-side, avoiding annotation size limits and enabling smooth incremental updates. (#793) - Enabled container image publishing to Github Container Registry (GHCR).(#1041)
- Support ARM container Images. (#1090)
Observability & Stability
- Shipped prebuilt Grafana dashboards covering control plane, gateway, and KV cache components for out-of-the-box observability. (#1048)
- Tuned Envoy proxy memory and buffer configurations for better performance under high concurrency. (#825)
- Tuned Envoy proxy configurations for memory and buffer management under high concurrency. (#967)
- Added graceful shutdown, liveness, and readiness probes to improve service resilience. (#962)
- Delivered production-ready monitoring setups for all major system components. (#1048)
Bug Fixes
This release includes over 40 bug fixes aimed at improving system robustness, correctness, and production readiness. Key fixes include:
OpenAI & vLLM Interface Compatibility (Gateway Plugin): Fixed request/response header handling, streaming token usage reporting, and error propagation. (#703, #788, #794, #1006)
Internal Cache Store & Controller Reliability: Resolved stale cache issues, incorrect informer setup, and controller cleanup handling. (#763, #925, #926, #937, #938, #981, #1015)
Autoscaling Stability: Addressed metric fetching failures, locking issues and HPA sync correctness. (#860, #934, #1039, #1044)
Gateway Stability: Improved rate limiting keys, Redis client lifecycle, and reference grant cleanup behavior. (#968, #987, #1056)
Contributors & Community
v0.3.0 is one of our most collaborative releases to date, with 35 contributors bringing diverse improvements across control plane, data plane, docs, and developer tools.
Special thanks to contributors who drove key features and improvements in this release:
- KVCache Offloading and Distributed KV orchestration: @DwyaneShi @Jeffwan
- Infinistore: @thesues @hhzguo @XiaoningDing
- Routing & Gateway enhancements: @varungup90, @gangmuk, @Venkat2811, @zhangjyr, @Xunzhuo
- Benchmark toolkit: @happyandslow @duli2012
- Stability Improvements: @googs1025 @Iceber @kerthcet
We’re also thrilled to welcome many first-time contributors to the AIBrix community:
@gaocegege, @eltociear, @terrytangyuan, @jolfr, @Abirdcfly, @pierDipi, @Xunzhuo, @zjd0112, @SongGuyang, @vaaandark, @vie-serendipity, @nurali-techie, @legendtkl, @ronaldosaheki, @nadongjun, @cr7258, @thomasjpfan, @runzhen, @my-git9, @googs1025, @Iceber, @ModiIntel, @Venkat2811, @SuperMohit, @weapons97, @zhixian82
Thank you for your valuable contributions and feedback—keep them coming!
Next Steps
We’re actively evolving AIBrix to support more advanced and production-ready LLM serving capabilities. For v0.4.0 and beyond, our roadmap includes:
Prefill & Decode Disaggregation: Enable architectural support for separating prefill and decode stages across devices or nodes to maximize throughput and resource utilization.
KVCache Offloading Framework Evolution: Extend support to the vLLM v1 architecture, which introduces layer-by-layer pipelined KV transmission—enabling lower latency and better parallelism compared to the v0 design.
Multi-Tenancy & Isolation: Introduce tenancy as a first-class concept in AIBrix—supporting per-tenant model isolation, request segregation, and fine-grained SLO control for production use cases.
Batch Inference & Request Collocation: Optimize request routing across heterogeneous GPU types to improve cost-efficiency, particularly under mixed workload conditions.
Stay tuned for our upcoming v0.4.0 roadmap! If you’re interested in contributing new features or helping shape the direction of AIBrix, we’d love to hear from you.
Have a feature request in mind? Feel free to leave a comment on this issue.
Looking to collaborate or get involved? Don’t hesitate to reach out—we welcome all contributions!