We’re excited to announce the v0.2.0 release of AIBrix! Building on feedback from v0.1.0 production adoption and user interest, this release introduces several new features to enhance performance and usability.
- Extend the vLLM Prefix Cache with external distributed Dram based KV Cache pool
- Mix-Grain Multi-Node Inference Orchestration
- Cost efficient and SLO-driven Heterogenous Serving
- Accelerator Diagnostic and Failure Mockup Tools
What’s New?
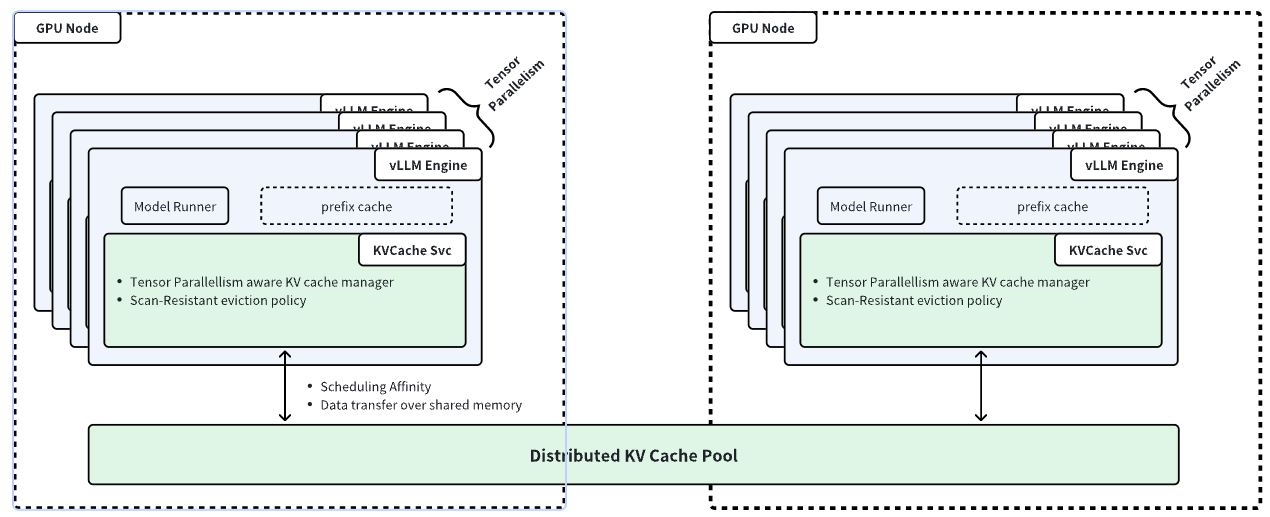
Distributed KV Cache Pool
The rising demand for large language models has intensified the need for efficient memory management and caching to optimize inference performance and reduce costs. In multi-round use cases like chatbots and agent-based systems, overlapping token sequences lead to redundant computations during the prefill phase, wasting resources and limiting throughput.
Many inference engines, such as vLLM, use built-in KV caching to mitigate this issue, leveraging idle HBM and DRAM. However, single-node KV caches face key limitations: constrained memory capacity, engine-specific storage that prevents sharing across instances, and difficulty supporting scenarios like KV migration and prefill-decode disaggregation.
AIBrix addresses these challenges with a distributed KV cache, enabling high-capacity, cross-engine KV reuse while optimizing network and memory efficiency. Our solution employs a scan-resistant eviction policy to persist hot KV tensors selectively, ensuring that network and memory usage is optimized by minimizing unnecessary data transfers, asynchronous metadata updates to reduce overhead, and cache-engine colocation for faster data transfer via shared memory.
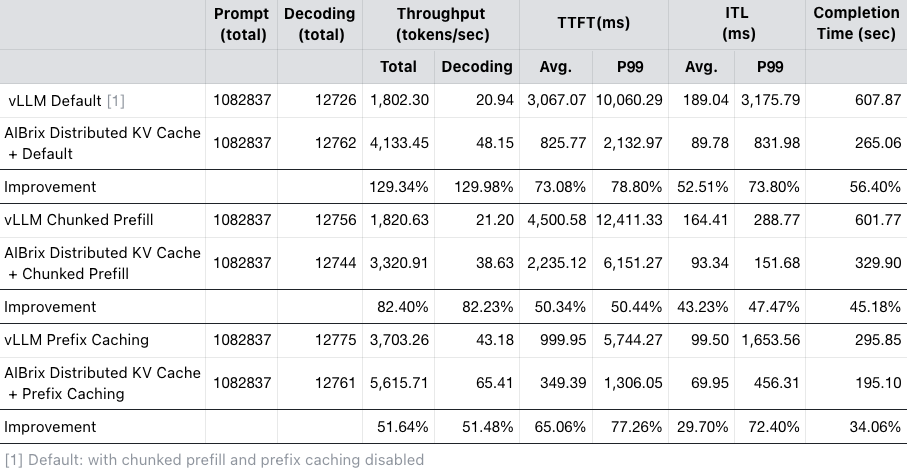
Benchmarking with Bird Text2SQL workloads shows that, even when compared to the prefix caching feature in vLLM, combining the distributed KV cache with prefix caching improves peak throughput by ~50%, reduces average and P99 TTFT by ~60% and ~70%, and lowers average and P99 ITL by ~30% and ~70%, demonstrating significant efficiency gains. A more detailed comparison is summarized in the following table.
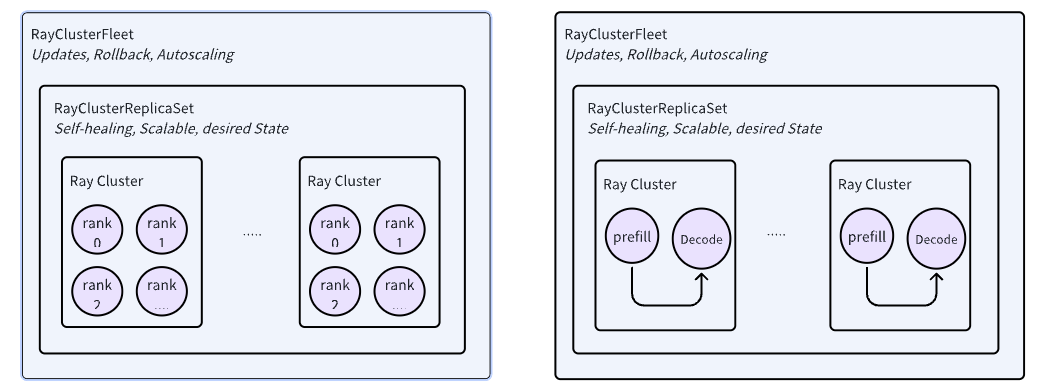
Mix-Grain Multi-Node Inference Orchestration
The release of Llama 3 (405B) and Deepseek-R1 (671B) has driven demand for multi-node inference, yet frameworks like vLLM prioritize parallelism over service-oriented needs like scaling and rolling upgrades, requiring external orchestration. In the landscape of distributed computing, both Kubernetes and Ray offer orchestration capabilities but with trade-offs: Kubernetes operators can be overly complex for fine-grained scheduling, while Ray excels in distributed communication but lacks broader resource management.
We propose a hybrid approach combining Ray for fine-grained application orchestration and Kubernetes for coarse-grained resource management, simplifying operator design while improving flexibility and efficiency. This method is informed by Bytedance’s internal experience in hosting Kubernetes and Ray workloads, addressing challenges where workload communication patterns often require frequent orchestration adjustments.
Cost-efficient and SLO-driven Heterogenous Serving
Literature such as Melange and QLM has figured out that the throughput of LLM serving under specific SLO is a function of (# input tokens, # output tokens, model) under heterogeneous GPUs environments.
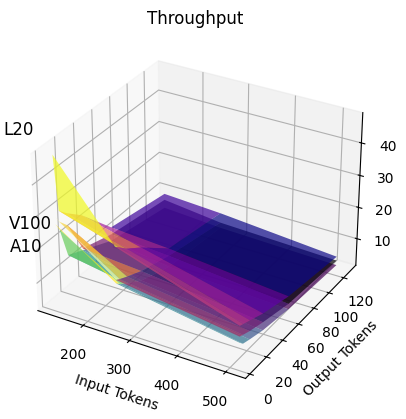 Throughputs of workload using the deepseek-coder-7b model on L20, V100 and A10 GPU
Throughputs of workload using the deepseek-coder-7b model on L20, V100 and A10 GPU
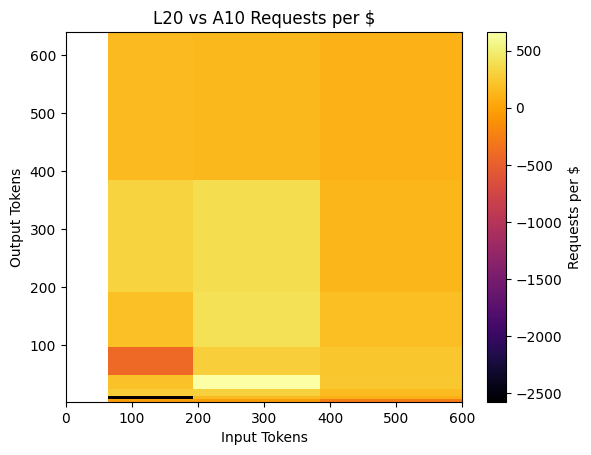 While most requests of different (# input tokens, # output tokens) pairs prefer L20 for cost-efficiency, requests of # input tokens < 200, # output tokens < 100 prefer A10.
While most requests of different (# input tokens, # output tokens) pairs prefer L20 for cost-efficiency, requests of # input tokens < 200, # output tokens < 100 prefer A10.
Furthermore, when considering requests per dollar, different GPUs exhibit varying efficiency across different input-output token distributions, even for the same model, as shown above. In addition, production users frequently face GPU availability constraints, making it difficult to consistently access the same GPU types.
To address these challenges, AIBrix introduces a GPU optimizer that works as an independent off-path component designed to optimize heterogeneous GPU serving. Below is the high-level architecture:
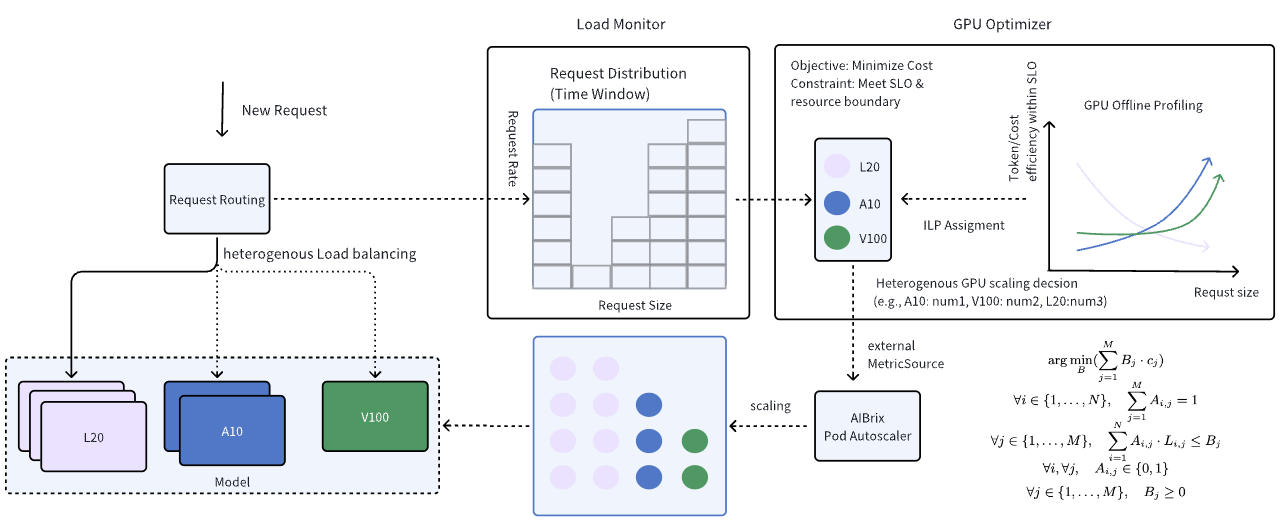
How does it work?
- The Load Monitor tracks deployment changes, assumes different deployments of the same model use different GPUs. It also analyzes statistics from the AIBrix Gateway to identify dominant workload patterns (# input/ # output tokens).
- The GPU Optimizer dynamically selects the optimal GPU combination to balance cost-efficiency while meeting SLOs.
- AIBrix’s PodAutoscaler reads external MetricSource data from the GPU Optimizer to adjust GPU allocation. Currently, the GPU optimizer supports an ILP solution proposed in Melange and needs pre-deployment profiling. AIBrix provides the necessary toolkits for workload benchmarking and profile generation.
In our experiment comparing heterogeneous workloads (using A10 and L20) against a homogeneous setup (using only L20), we evaluated a mixed dataset consisting of ShareGPT and Text2SQL workloads. Under the heterogeneous configuration, the GPU optimizer led to a latency increase of up to 20% while still remaining within the specified SLO. However, this setup reduced costs by approximately 10% compared to the homogeneous GPU deployment.
AI Accelerator Diagnostic and Failure Mockup Tools
GPU failures and performance degradation pose significant challenges in large-scale AI deployments. Silent errors, overheating, memory leaks, and intermittent failures can lead to degraded model performance, increased latency, or even system crashes. Many production users struggle with diagnosing GPU issues in heterogeneous environments, where different GPU models behave inconsistently under varying workloads.
To address these challenges, AIBrix Accelerator Tools introduces:
- GPU Diagnostics & Issue Identification – Automates fault detection, helping users identify and resolve GPU-related performance issues before they impact workloads.
- GPU Failure Mock-Up Tools – Simulates GPU failures, enabling developers to test and build resilient AI frameworks that gracefully recover from hardware failures. Now, Nvidia GPUs and Ascend 910B NPUs are supported. We will extend support for more accelerators.
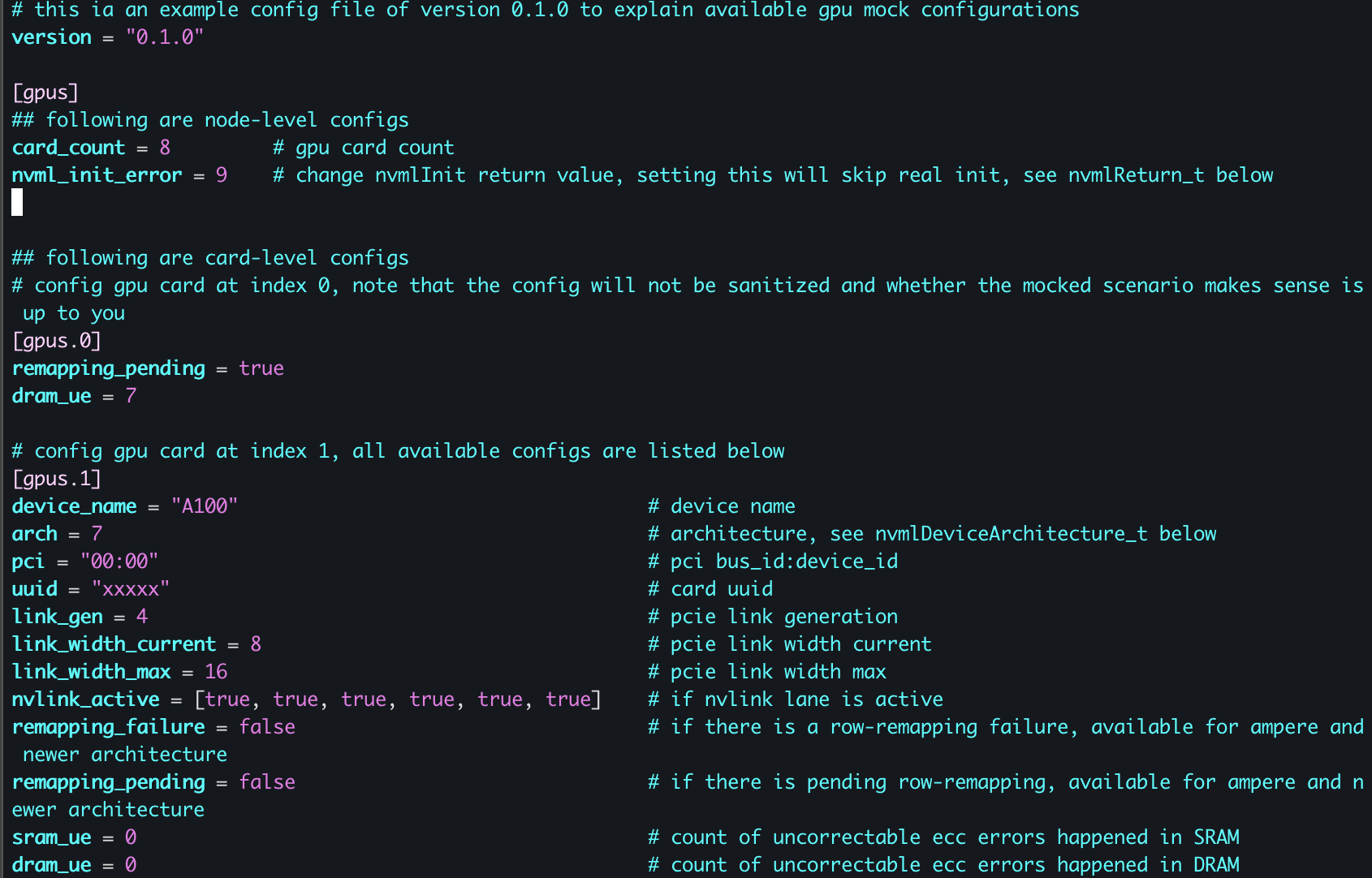
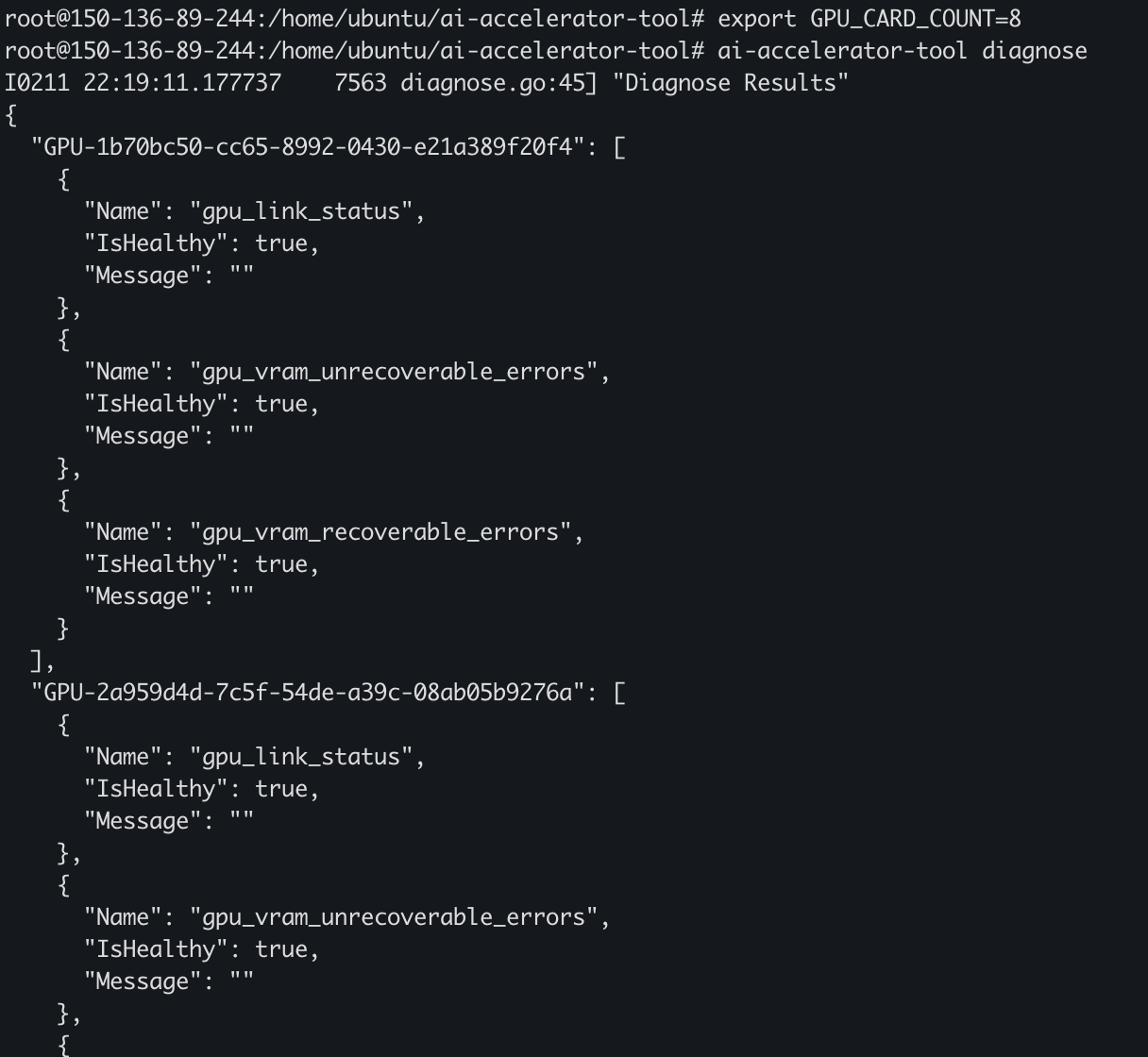
Here’s an example that it mocks the missing NvmlInit Error and diagnoses the GPU failure.
Future works
AIBrix v0.2.0 introduces several co-designed features between engines and systems, a strategy we believe is crucial for optimizing performance. Moving forward, we plan to continue exploring this approach by developing initiatives such as standardizing the KV Cache API for use with external KV pools in prefix cache scenarios, plugging AIBrix distributed KV cache pool for Prefill & Decode (P&D) disaggregation, considering roofline-based models to streamline profiling processes in heterogeneous routing, and enhancing distributed orchestration to better support large-scale models like DeepSeek R1 and various offline scenarios.
To start building your AI infrastructure with AIBrix, join our Slack Channel and contribute to the future of open, scalable AI infrastructure.