In recent years, large language models (LLMs) have revolutionized AI applications, powering solutions in areas like chatbots, automated content generation, and advanced recommendation engines. Services like OpenAI’s have gained significant traction; however, many enterprises seek alternatives due to data security concerns, customizability needs, or the financial impact of proprietary solutions. Yet, transforming LLMs into cost-effective, scalable APIs poses substantial technical challenges.
Key Challenges in AI Infrastructure
- Efficient Heterogeneous Resource Management: Managing GPU resources across clouds is crucial for balancing cost and performance. This involves autoscaling, high-density deployments, and efficiently handling mixed GPU types to reduce expenses and support peak loads without over-provisioning.
- Next-Gen Disaggregation Architectures: Cutting-edge architectures, like prefill and decoding disaggregating or employing a remote KV cache, enable more granular resource control and reduce processing costs. However, they demand significant R&D investment to develop reliable, scalable implementations.
- Operating LLM Services at Scale: Ensuring reliable, scalable LLM services on the cloud requires complex service discovery, multi-tenant scheduling, and robust fault-tolerant mechanisms to handle failures and ensure fair resource allocation.
To address above challenges, we developed AIBrix. AIBrix is a cloud-native, open-source framework designed to simplify and optimize LLM deployment, offering flexibility and cost savings without sacrificing performance. Our initial release, version 0.1.0, brings together four key innovations to streamline enterprise-grade LLM infrastructure, enhancing scalability and efficiency.
AIBrix v0.1.0: Key Features and Innovations
AIBrix provides an infrastructure that addresses these challenges head-on with a cohesive suite of tools and features. Here’s a look at the four core components that make AIBrix a powerful solution for scalable LLM deployments.
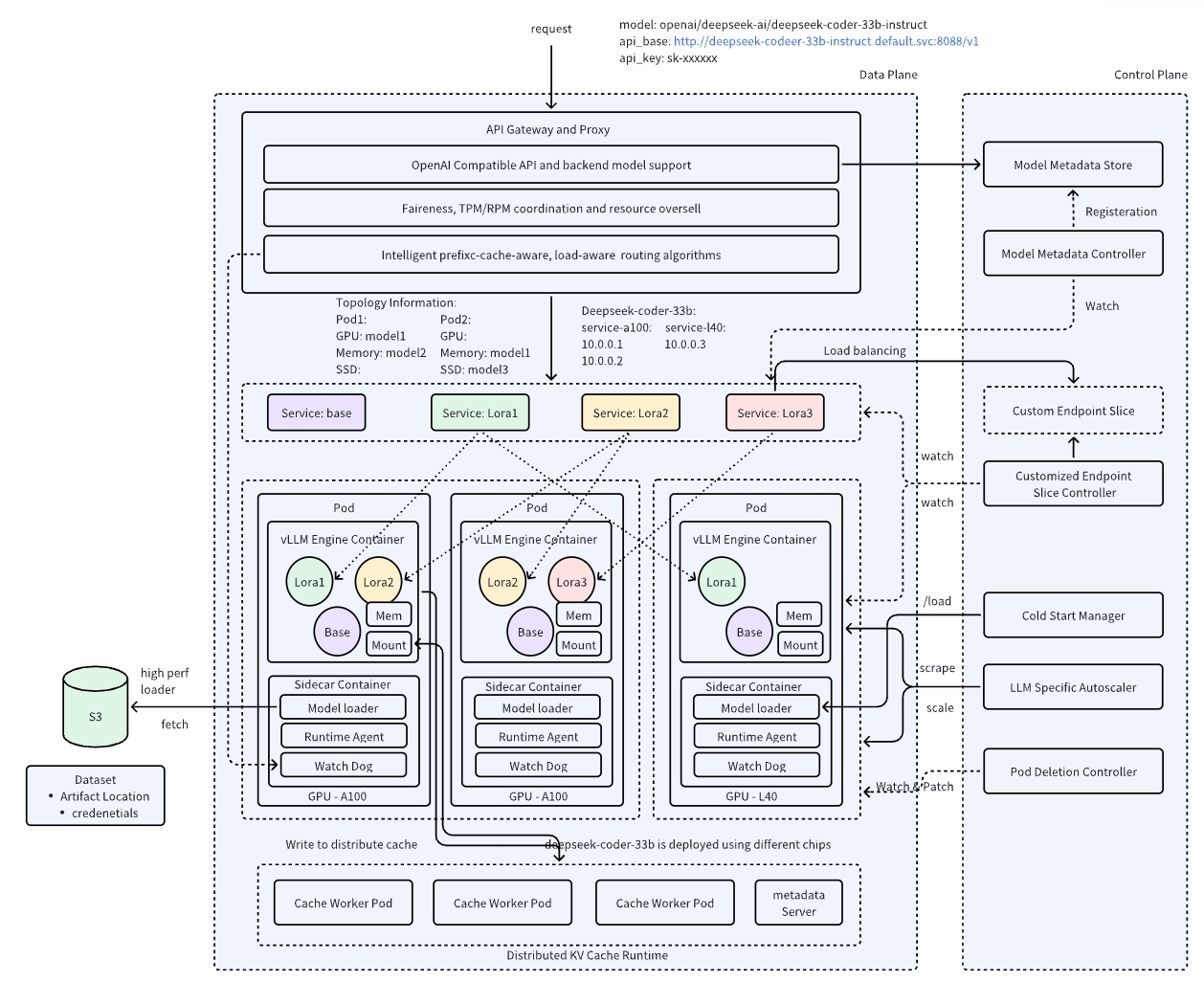
High-Density LoRA Management: Cost-Effective Model Adaptation
Deploying LoRA (Low-Rank Adaptation) models at scale has traditionally been constrained by static deployments, limiting flexibility and driving up costs. Most serving infrastructures treat LoRA models as fixed additions to a base model, making dynamic scaling impractical. Without resource managers’ integration, lora evictions, failure handling remain unreliable, and resource allocation becomes inefficient.
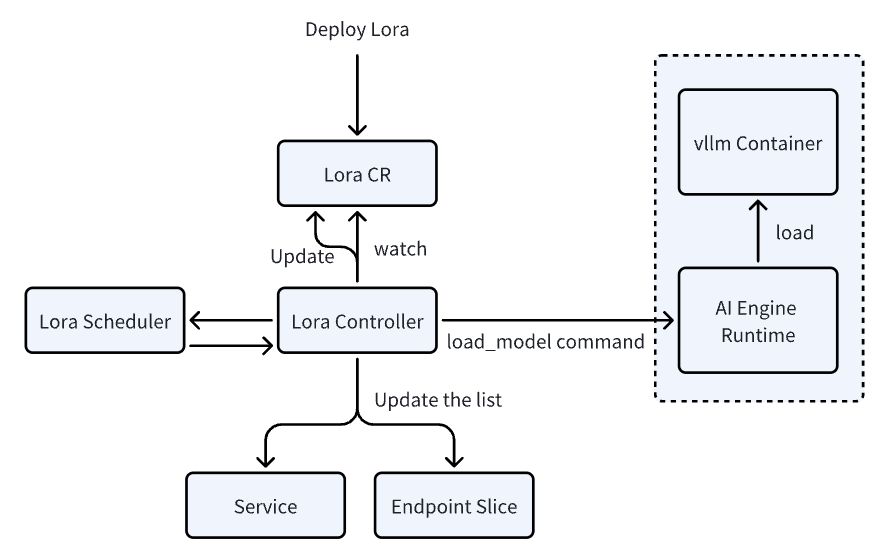
AIBrix introduces high-density LoRA management, enabling dynamic adapter loading/unloading, intelligent scheduling, and LoRA-aware routing to optimize inference efficiency. By dynamically registering LoRA adapters, we enable high-density model deployment, significantly reducing inference costs—making it an ideal solution for long-tail scenarios. AIBrix leverages Kubernetes’ built-in mechanisms, such as Service and EndpointSlice, for efficient LoRA model service discovery. We are also developing strategies to ensure models are placed on optimal pods with minimal interference. Beyond system-level improvements, we have introduced enhancements in vLLM to strengthen LoRA management capabilities. This design not only reduces operational overhead but also improves inference performance under mixed workloads.
The results? A 4.7× cost reduction in low-traffic scenarios and 1.5× savings even under high demand, all while maintaining seamless performance and eliminating bottlenecks in LoRA deployment workflows.
Advanced LLM Routing Strategies
Traditional API gateways struggle with LLM inference due to the wide variability in request complexity—from simple queries to multi-turn conversations with intricate token interactions. Generic routing fails to optimize for these nuances, causing inefficient traffic distribution and latency spikes.
AIBrix solves this with an LLM-aware gateway, extending Envoy to support instance routing, prefix-cache awareness, and least-GPU-memory-based strategies. Instead of blindly distributing requests, our routing engine analyzes token patterns, prefill cache availability, and compute overhead to optimize traffic flow. This enables advanced features and allows users to integrate custom routing strategies.
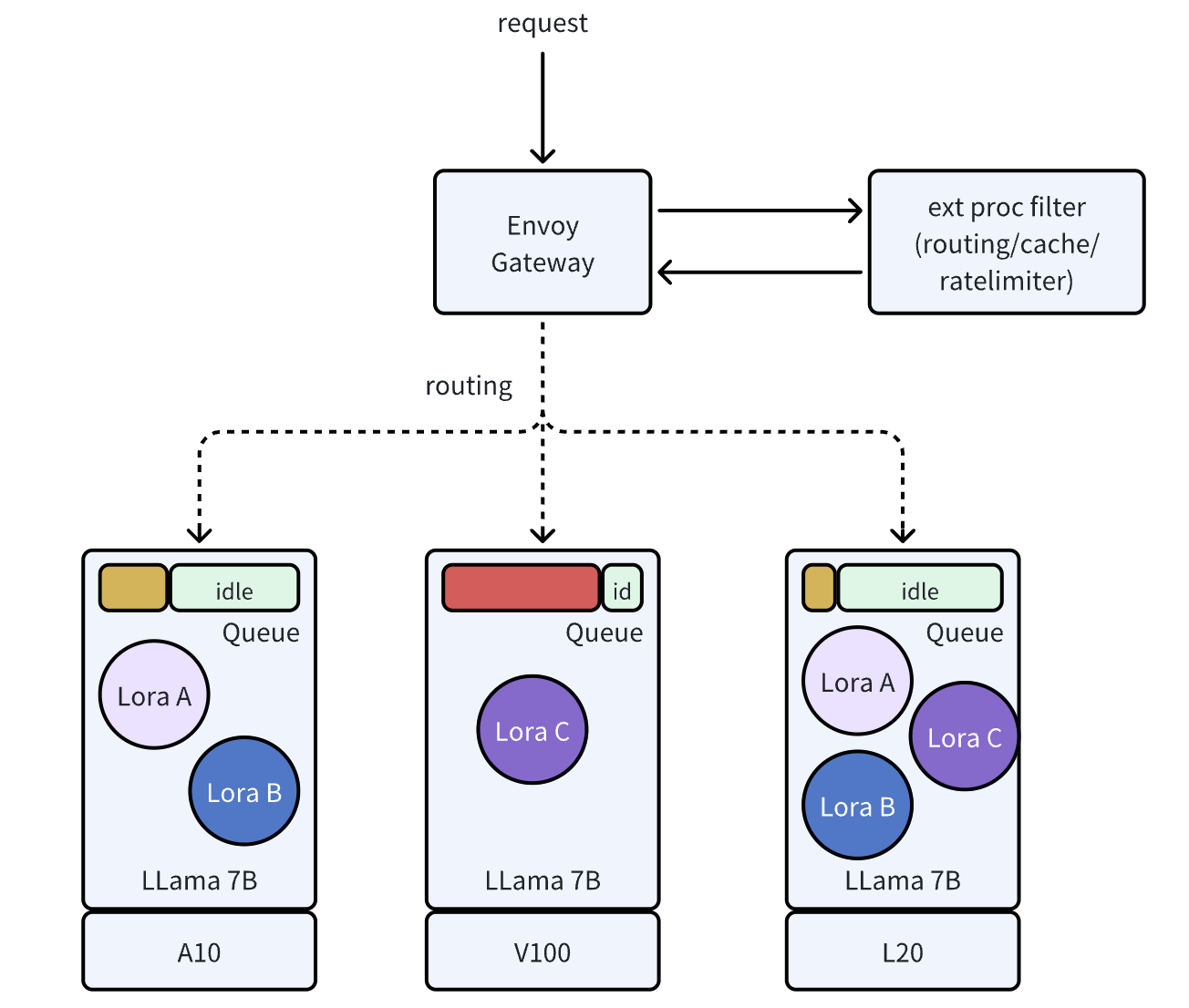
We are also collaborating with Google and Kubernetes WG-Serving on the Gateway API Inference Extension to drive scalable, standardized solutions. By adopting least-GPU-memory strategies, AIBrix reduces mean latency by 19.2% and P99 latency by 79%, making it a game-changer for efficient, fair LLM inference at scale.
Unified AI Runtime
AIBrix introduces a unified AI runtime and it serves as an essential bridge between the AIBrix Control Plane and inference engine pods, enabling model management, engine configuration, observability, and vendor-agnostic engine support. The runtime ensures seamless communication between the control plane and inference pods. This allows components like the LoRA adapter controller, autoscaler, and cold start manager to interact dynamically with inference containers, managing resources in a cloud-native way. The other important role is to abstract Vendor-Specific APIs and it is designed to work with diverse inference engines. Now, only vLLM is supported.
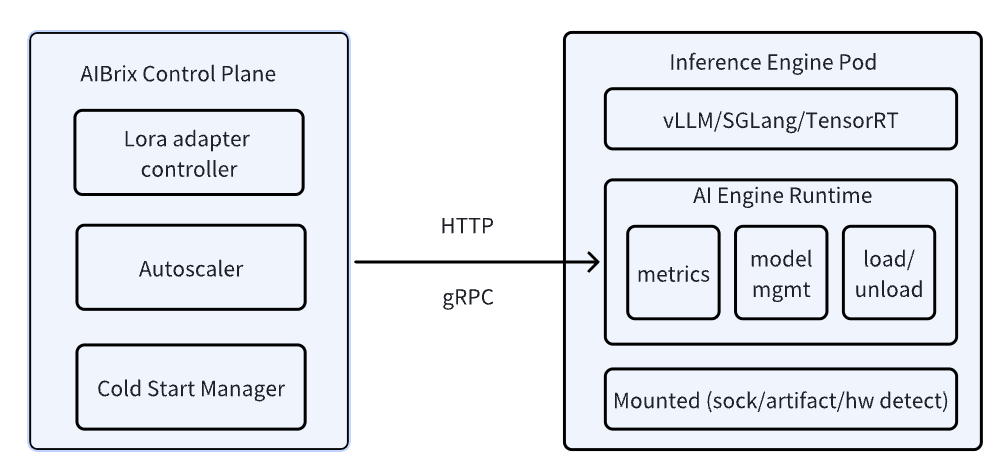
We also introduce a GPU stream loader which directly streams tensors from remote storage into GPU memory, bypassing the usual disk IO overhead. This is still in downstream open source branch and will make it upstream soon. The loading pathway speeds up by 41.5% in volcano engine cloud and it natively supports safetensor format.
LLM-Specific Autoscaling
Autoscaling for LLM inference is challenging due to DCGM metric limitations, non-linear scaling behaviors, and the inadequacy of traditional indicators like QPS or concurrency. Request complexity and input/output size vary widely, often overwhelming systems before autoscalers can react. Additionally, large GPU images and slow model distribution introduce a 2-3 minute delay for new pods to become operational, making rapid scaling inefficient.
AIBrix tackles these issues with LLM-specific autoscaling, replacing Prometheus-based polling with sliding window metric aggregation for real-time load reporting. By leveraging advanced autoscaling algorithms like KPA or APA, our approach achieves an 11.5% reduction in latency, an 11.4% increase in token throughput, and 33% fewer scaling oscillations compared to native HPA. Looking ahead, we’re exploring token-based proactive scaling and SLO-driven autoscaling to further enhance efficiency and responsiveness.
Building the Future of Scalable AI with AIBrix
AIBrix v0.1.0 delivers a comprehensive, open-source toolkit designed to address the needs of enterprises deploying LLMs at scale. By combining high-density LoRA management, an advanced LLM gateway, a GPU-optimized runtime, and LLM-specific autoscaling, AIBrix enables efficient, cost-effective AI infrastructure. Whether you’re an end user or a model vendor, AIBrix brings operational flexibility, enhanced scalability, and significant cost savings to your AI deployments.
To start building your AI infrastructure with AIBrix, join our community and contribute to the future of open, scalable AI infrastructure.